2주차에는 numpy, list vs np.array, slicing, boolean 인덱싱, randn 함수, sort(오름차순), reshape에 대해 배웠다.
이후 데이터를 colab으로 읽어들이고 여러 함수들을 써서 그래프를 시각화하는 연습을 했다.
이를 위해 Matplotlib, Seaborn 등을 사용하였다.
0) 설치
기본설치
##matplotlib 설치
!pip install matplotlib
import matplotlib.pyploy as plt
import matplotlib
import pandas as pd
print(matplotlib.__version__)
글꼴 설치(한글용)
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf 하고
import matplotlib.pyplot as plt
plt.rc('font',family='NanumBarunGothic')
plt.rcParams['axes.unicode_minus']=False
1) 실습1) git에서 자료 가져오기
!git clone https://github.com/MainakRepositor/Datasets.git
2) csv 파일 Pokemon.csv 가져오기
df = pd.read_csv("/content/Datasets/Pokemon.csv")
3) 위에서 부터 20줄 가져오기
df.head(n=20)

4) 히스토그램
df에서 speed열을 가져와서 x축 개수를 30으로 한정해서 히스토그램으로 표현한다.
plt.hist(df['Speed'],edgecolor="#0000a0", color="#0000ff",bins=30)

5) 상자그림 (포켓몬 문제)
조건) 박스그림 함수를 이용할 것인데, 행을 그리고,색을 채우고, 박스모양을 가운데가 오목 들어간 모양으로 바꿀것이다.
데이터의 평균은 표시하지 않는다. 중간값 색과 너비를 설정할 것이며, 박스의 face 색과 가장자리 색을 설정 할 것이다.
더불어 박스 상단 세로선에 대한 설정을 넣을 것이다.
코드) boxplot이며 loc으로 위치를 지정한다. patch_artist로 상자 부분이 패치 아티스트로 그려진다. 이는 상자의 색상을 변경하거나 다양한 그래픽 속성을 조정하는 데 사용된다. notch는 박스의 가운데가 오목 들어가게 한다.
plt.boxplot([df.loc[df['Legendary']==True]['Attack'],df.loc[df['Legendary' ]==False]['Attack']],
widths=0.3, patch_artist=True, notch=True, showmeans=False,
labels=['전설 포켓몬','일반 포켓몬'],
medianprops={"color": "white", "linewidth": 0.5}, //중간값을 나타내는 선의 속성
boxprops={"facecolor": "C0", "edgecolor": "white", "linewidth": 0.5},
whiskerprops={"color": "C0", "linewidth": 1.5}, //수염 부분의 속성(상자의 위아래에 그려지는 선분 / 최대,최솟값 표현)
capprops={"color": "C0", "linewidth": 1.5} // 상자 그림의 상단 막대 부분의 속성

6) 글꼴 설치
!sudo apt-get install -y fonts-nanum # 나눔체 설치
!sudo fc-cache -fv # 폰트 캐시 갱신
!rm ~/.cache/matplotlib -rf #matplotlib 캐시 삭제
Pyplot의 글꼴 설정 기능을 이용하여, 나눔바른고딕체로 폰트를 설정하고자 한다
plt.rc('font',family='NanumBarunGothic')
plt.rcParams['axes.unicode_minus'] =False
7) 바이올린 그림
plt.violinplot(df['Defense'], vert=False, showmeans =True, points=200)
plt.show()
vert는 vertical 수직으로 그리냐인데 false라 수평이고 / showmeans는 선으로 평균이 나타난거고 /
points는바이올린 플롯의 윤곽을 나타내는 점의 개수라 많을수록 부드럽

8) 히트맵
plt.hist2d(df['Attack'],df['Defense'], bins=([x for x in range (0,230,5)], [j for j in range(0,200,5)]), cmap='plasma')
plt.show()
bins: 히스토그램을 그릴 때 데이터를 나누는 구간의 수를 지정하는 매개변수이다.
cmap: 컬러맵(Color Map)을 지정하는 매개변수이다. 시각화에서 사용되며 데이터의 값을 색상으로 표현하는 데 활용된다.

9) 산점도
plt.scatter(x=df['HP'],y=df['Total'], marker='x',c='#000000') // 산점도를 그리고 점 대신 x로 표시한다

10) ##seaborn 설치
!pip install seaborn
import seaborn as sns
import pandas as pd
sns.__version__
11) 실습2) git에서 자료가져오기
!git clone "https://github.com/rashakil-ds/Public-Datasets.git"
!git clone "https://github.com/google/dspl.git"
!git clone https://github.com/kirenz/datasets.git
12) csv 파일 읽기
train=pd.read_csv("/content/Public-Datasets/bank.csv")
train
train_2 = pd.read_csv("/content/dspl/samples/eurostat/population_density/met_d3dens.csv")
train_2
train_3 = pd.read_csv("/content/datasets/Auto.csv")
train_2
13) 히스토그램1
sns.displot(data=train['month'])

14) 히스토그램2
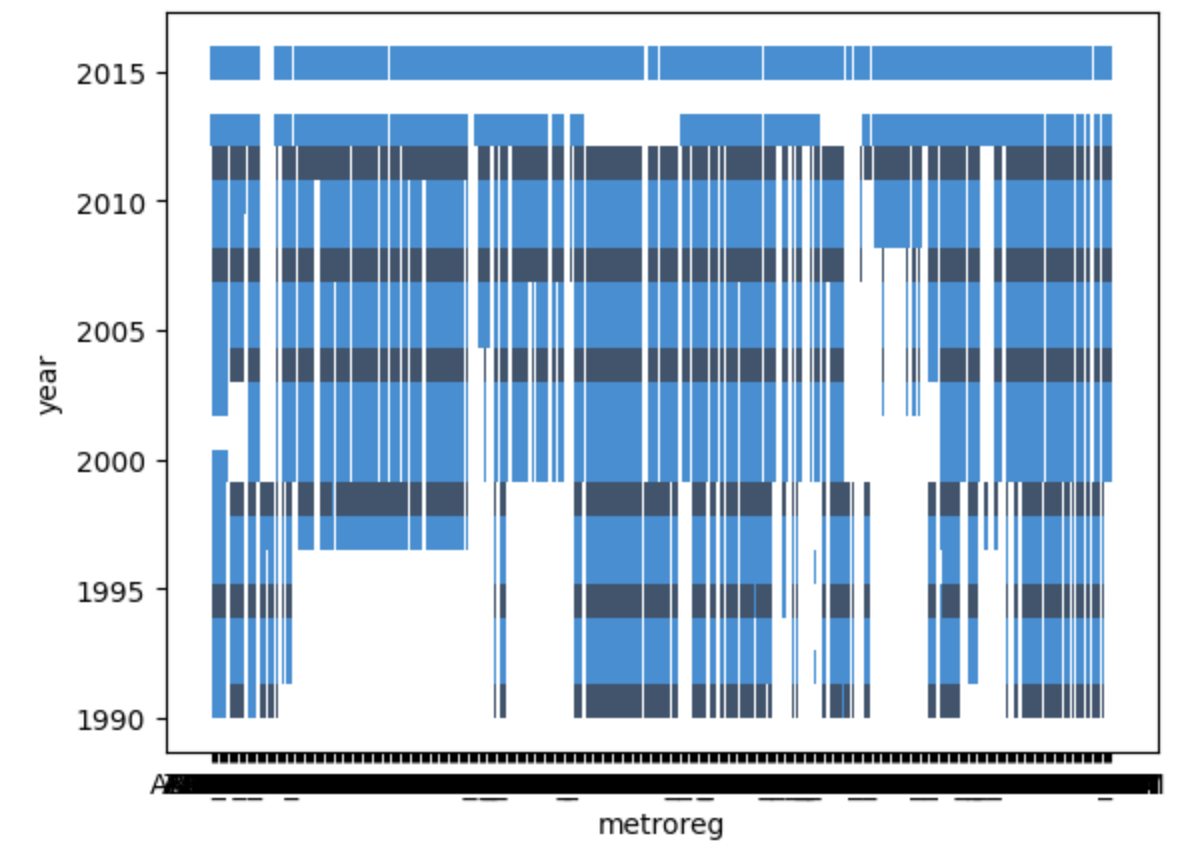
train 데이터프레임에서 Metroreg랑 month 열을 가져와 가로축에 month 세로축에 year가 있는 히스토그램
sns.histplot(x=train_2['metroreg'], y=train_2['year'])
15) Kernel Density Plot
히스토그램의 단점을 보완하기 위해 제안 된 방식으로, 히스토그램이 구간별 데이터 수를 bar plot으로 표현하는 방식이라면,
Kernerl Density Plot은 각 데이터로 밀도 분포를 추정하여 합산하는 방식
16) KNP
train_2 데이터프레임에서 year열을 가져와, 가로열을 year로 설정한 후, Kernel Density Plot을 시각화한다.
sns.kdeplot(x= train_2['year']) //kernel density estimate에 대한 그래프 반환

17) KDP
Train_2 데이터프레임에서 density과 year열을 가져와, 가로축은 density, 세로축은 year가 배치된 Kernel Density Plot을 시각화한다
sns.kdeplot=(x=train_2['density'], y=train_2['year'])

18) Empirical Cumulative Distribution Functions Plot (경험적 누적분포 함수)
주어진 데이터의 누적 분포를 시각화하는 함수이다.
데이터 분포의 적합(fit)을 평가하거나 서로 다른 여러 표본 분포를 비교할 때 사용한다.

예를 들어 위와 같이 총 12개의 정렬된 데이터를 사용하였다.
-이 데이터에 대해 경험적 누적분포함수를 그리게 되면 계단식 그래프가 생성된다. 첫번째 관측 값 13이 x 축에 표시되었으며, 이 데이터가 전체에서 차지하는 비중은 Y에 표시되며 8.33%이다. (전체 관측 값 개수가 12개 이기 때문에 1/12 * 100 = 8.33%)
-두 번째 관측 값(2번째 계단)은 19이다. 19에 해당하는 계단에 마우스를 올려 보면 누적확률이 16.66%가 표시된다. (= 8.33% (관측값 13) + 8.33% (관측값 19)). 다음으로 x 값 23(4번째 계단)을 보면 계단이 가파르고, 그 누적확률이 50%가 된다. 그 이유는 x가 23인 관측 개수가 3개 있기 때문이다.
19) ECDF plot
train_3 데이터프레임에서 displacement열을 가져와, 가로열을 displacement로 설정한 후 시각화한다.
sns.ecdfplot(x= train_3['displacement'])

20) 작은 선분 그림
데이터 분포의 개별 관측 값을 축에 직선으로 표시하는 시각화 방법이다.
21) kde와 rug
train_3 데이터프레임에서 displacement열을 가져와, 앞서 쓴 seaborn 함수 중 하나와, 작은 선분 그림 함수 하나를 동시에 시각화한다.
sns.kdeplot(x=train_3['displacement'])
sns.rugplot(x=train_3['displacement'])

22) 막대그래프 그림
막대 그래프 그림 함수는 범주형 데이터의 중심 경향성을 나타내는 막대 그래프를 생성하는데 사용된다.
데이터셋에서 x 축에 따른 y축의 평균값을 막대 그래프로 시각화하는데 사용된다.
23) 막대그래프
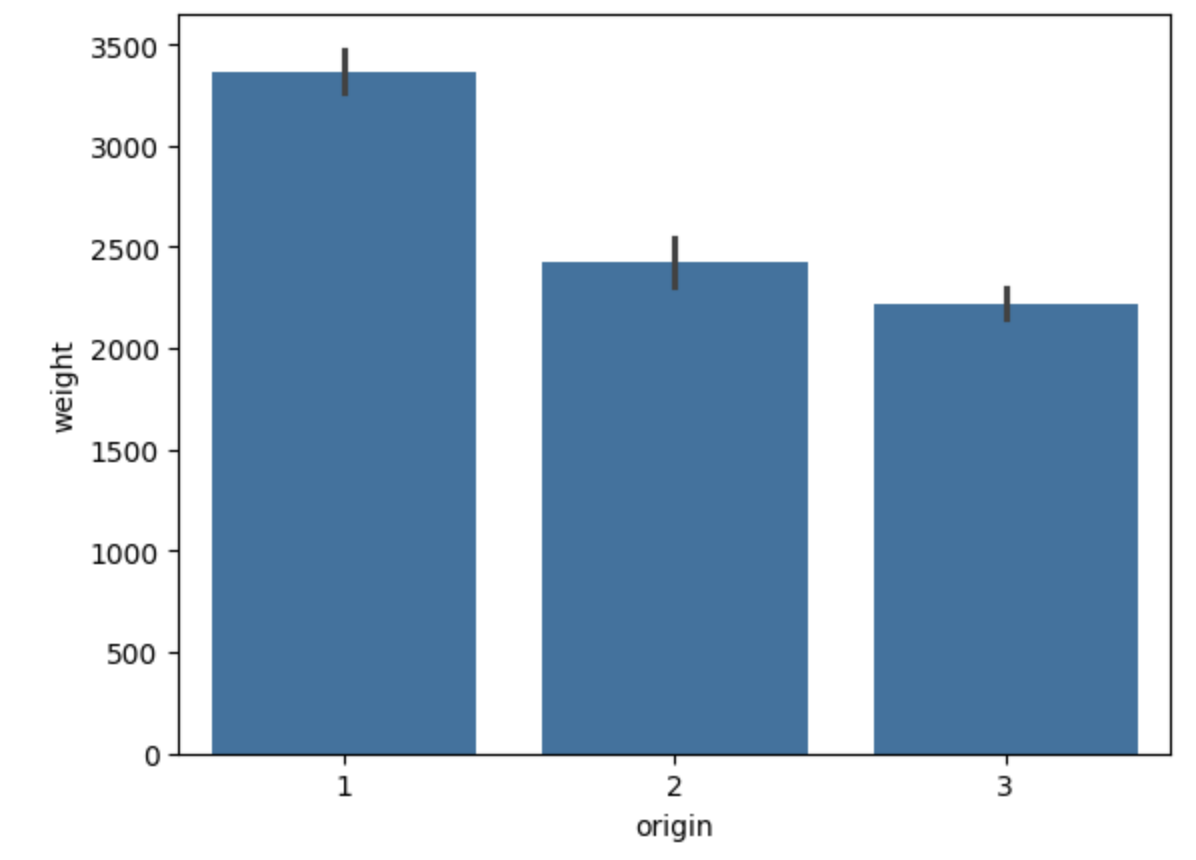
sns.barplot(x= train_3['origin'],y=train_3['weight'])
train_3 데이터프레임에서 origin열과 weight열을 가져와, 막대 그래프 함수로 시각화한다.
24) 상자그림
상자 그림은 데이터의 분포와 중앙값, 최대, 최소 등을 시각적으로 표현하는데 사용된다.
자료로부터 얻어낸 통계량인 5가지 요약수치(제 1사분위, 제 2사분위, 제 3사분위, 최댓값, 최솟값)을 일컫는 말이다. ( 제 3사분위 수 (Q3) : 중앙값 기준으로 상위 50% 중의 중앙값, 전체 데이터 중 상위 25%에 해당하는 값 / 제 1사분위 수 (Q1) : 중앙값 기준으로 하위 50% 중의 중앙값, 전체 데이터 중 하위 25%에 해당하는 값)
<그리는 법>
-최소값과 최대값으로 인해 상자의 수염의 길이가 결정
-제 1사분위수와 제 3사분위수의 값으로 인해 상자의 길이가 결정
-중앙값이 상자 가운데 선의 위치를 결정
- 크기순 재정렬
- 사분위수를 결정
- 제 1사분위수와 제 3사분위수를 네모난 상자로 연결
- 중앙값 위치에 수직선 긋기
- 사분위수 범위 계산
- 상자 양끝에서 1.5*사분위수 범위 크기의 범위를 경계로, 이 범위에 포함되는 최소값과 최대값을 제 1사분위수와 제 3사분위수로부터 각각 선으로 연결
- 경계를 벗어나는 관측값은 이상치(Outliers)로 표시

25) 상자그림
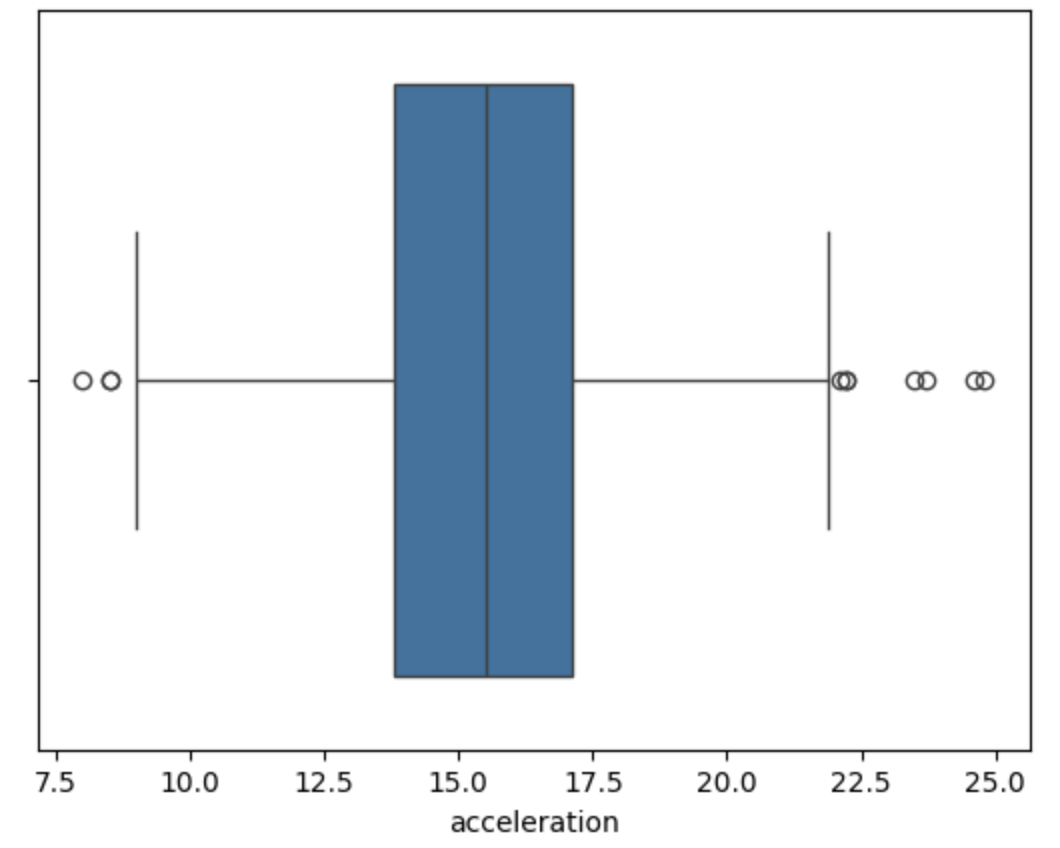
train_3 데이터프레임에서 acceleration열을 가져와, 상자 그림 함수를 그린다.
sns.boxplot(x= train_3['acceleration'])
'matrix' 카테고리의 다른 글
| 음악 장르 분류 (0) | 2024.07.29 |
|---|---|
| Matrix - 8주차 스터디 (0) | 2024.05.24 |
| Matrix-4주차 스터디 (0) | 2024.04.12 |
| Matrix-1주차 스터디 (0) | 2024.03.21 |

