출처: 딥 러닝을 이용한 자연어 처리 입문 (위키북스)
링크: https://wikidocs.net/book/2155
Embedding Layer
워드 임베딩(Word Embedding): 단어를 벡터로 표현하는 방법으로, 단어를 밀집 표현으로 변환한다.
1. 희소표현(Sparse Representation)
원-핫 벡터들은 표현하고자 하는 단어의 인덱스의 값만 1이고, 나머지 인덱스에는 전부 0으로 표현되는 방법이다. 이렇게 벡터 또는 행렬의 값이 대부분이 0으로 표현되는 방법을 희소 표현(sparse representation)이라고 한다. 원-핫 벡터는 희소 벡터이다.
이러한 희소 벡터의 문제점은 단어의 개수가 늘어나면 벡터의 차원이 한없이 커진다는 점이다. 원-핫 벡터로 표현할 때는 갖고 있는 코퍼스에 단어가 10,000개였다면 벡터의 차원은 10,000이어야만 했다. 심지어 그 중에서 단어의 인덱스에 해당되는 부분만 1이고 나머지는 0이다. 단어 집합이 클수록 고차원의 벡터가 된다. 예를 들어 단어가 10,000개 있고 인덱스가 0부터 시작하면서 강아지란 단어의 인덱스는 4였다면 원 핫 벡터는 { 강아지 = [ 0 0 0 0 1 0 0 0 0 0 0 0 ... 중략 ... 0] # 이때 1 뒤의 0의 수는 9995개. }로 표현된다.
이러한 벡터 표현은 공간적 낭비를 불러일으킨다. 희소 표현의 일종인 DTM과 같은 경우에도 특정 문서에 여러 단어가 다수 등장하였으나, 다른 많은 문서에서는 해당 특정 문서에 등장했던 단어들이 전부 등장하지 않는다면 역시나 행렬의 많은 값이 0이 되면서 공간적 낭비를 일으킨다.
2. 밀집표현(Dense Representation)
희소 표현과 반대되는 표현으로 밀집 표현이 있다. 밀집 표현은 벡터의 차원을 단어 집합의 크기로 상정하지 않는다. 사용자가 설정한 값으로 모든 단어의 벡터 표현의 차원을 맞춘다. 또한, 이 과정에서 더 이상 0과 1만 가진 값이 아니라 실수값을 가지게 된다.
밀집 표현을 사용하고, 사용자가 밀집 표현의 차원을 128로 설정한다면, 단어의 벡터 표현의 차원은 128가 되면서 모든 값이 실수가 된다.
Ex) 강아지 = [0.2 1.8 1.1 -2.1 1.1 2.8 ... 중략 ...] # 이 벡터의 차원은 128
이 경우 벡터의 차원이 조밀해졌다고 하여 밀집 벡터라고 한다.
3. 워드 임베딩 (Word Embedding)
단어를 밀집 벡터(dense vector)의 형태로 표현하는 방법을 워드 임베딩(word embedding)이라고 한다. 그리고 이 밀집 벡터를 워드 임베딩 과정을 통해 나온 결과라고 하여 임베딩 벡터(embedding vector)라고도 한다.
워드 임베딩 방법론으로는 LSA, Word2Vec, FastText, Glove 등이 있다. 케라스에서 제공하는 도구인 Embedding()는 앞서 언급한 방법들을 사용하지는 않지만, 단어를 랜덤한 값을 가지는 밀집 벡터로 변환한 뒤에, 인공 신경망의 가중치를 학습하는 것과 같은 방식으로 단어 벡터를 학습하는 방법을 사용한다.

정수를 임베딩 벡터로 맵핑한다는 것은 특정 단어와 맵핑되는 정수를 인덱스로 가지는 테이블로부터 임베딩 벡터 값을 가져오는 룩업 테이블이라고 볼 수 있다. 그리고 이 테이블은 단어 집합의 크기만큼의 행을 가지므로 모든 단어는 고유한 임베딩 벡터를 가진다.
위의 그림은 단어 great이 정수 인코딩 된 후 테이블로부터 해당 인덱스에 위치한 임베딩 벡터를 꺼내온 것이다.
단어 great은 정수 인코딩 과정에서 1,918의 정수로 인코딩이 되었고 그에 따라 단어 집합의 크기만큼의 행을 가지는 테이블에서 인덱스 1,918번에 위치한 행을 단어 great의 임베딩 벡터로 사용한다. 이 임베딩 벡터는 모델의 입력이 되고 역전파 과정에서 단어 great의 임베딩 벡터값이 학습된다.
from tensorflow.keras.layers import Embedding
model = Sequential()
model.add(Embedding(16, 4))
- Embedding(16, 4): 입력될 총 단어 수는 16, 임베딩 후 출력되는 크기는 4
- Embedding(16, 4, input_length=2)는 총 입력되는 단어 수는 16개이나 매번 단어를 2개씩만 넣겠다는 뜻이다.
→ 총 몇개의 단어 집합에서(입력), 몇 개의 임베딩 결과를 사용할 것인지(출력), 그리고 매번 입력될 단어의 수는 몇 개로 할지(단어수)를 정해야 한다.
순환 신경망 RNN(Recurrent Neural Network)
<정의>
순차 데이터나 시계열 데이터를 이용하는 인공 신경망 유형이다. 이 딥러닝 알고리즘은 언어 변환, 자연어 처리(nlp), 음성 인식, 이미지 캡션과 같은 순서 문제나 시간 문제에 흔히 사용된다. 그리고 Siri, 음성 검색, Google 번역과 같이 널리 쓰이는 애플리케이션에도 통합되어 있다. 피드포워드 및 컨볼루션 신경망(CNN)처럼 순환 신경망은 학습하는 데 훈련 데이터를 활용한다.
이 신경망은 과거의 입력으로부터 정보를 얻어 현재의 입력과 출력에 영향을 준다. 기존의 딥 신경망에서는 입력과 출력이 상호 독립적이라고 가정하지만, 순환 신경망의 출력은 시퀀스 내의 이전 요소에 의존한다. 미래의 이벤트도 지정된 시퀀스의 출력을 결정하는 데 도움이 되지만, 단방향의 순환 신경망의 경우 예측에서 이러한 이벤트를 설명할 수 없다.
<은닉 상태>
일부 신경망들은 은닉층에서 활성화 함수를 지난 값은 오직 출력층 방향으로만 향했다. 이 역할을 하는 노드를 (메모리)셀(cell)이라고 한다. 그리고 이와 같은 신경망들을 피드 포워드 신경망(Feed Forward Neural Network)이라고 한다.하지만 RNN은 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서, 다시 은닉층 노드의 다음 계산의 입력으로 보내는 특징을 갖고 있다.
은닉층의 메모리 셀은 각각의 시점(time step)에서 바로 이전 시점에서의 은닉층의 메모리 셀에서 나온 값을 자신의 입력으로 사용하는 재귀적 활동을 하고 있다. 현재 시점 t에서 메모리 셀이 갖고 있는 이 값은 뭐라고 부를까 메모리 셀이 출력층 방향 또는 다음 시점인 t+1의 자신에게 보내는 값을 은닉 상태(hidden state) 라고 한다. 다시 말해 t 시점의 메모리 셀은 t-1 시점의 메모리 셀이 보낸 은닉 상태값을 t 시점의 은닉 상태 계산을 위한 입력값으로 사용한다.
<수식>


RNN의 은닉층 연산을 벡터와 행렬 연산으로 이해해보자. 자연어 처리에서 RNN의 입력 xt는 대부분의 경우 단어 벡터로 간주할 수 있는데, 단어 벡터의 차원을 d라고 하고, 은닉 상태의 크기를 Dℎ라고 하였을 때 각 벡터와 행렬의 크기는 다음과 같다.

워드투벡터(Word2Vec)
원-핫 벡터는 단어 벡터 간 유의미한 유사도를 계산할 수 없다는 단점이 있다.
그래서 단어 벡터 간 유의미한 유사도를 반영할 수 있도록 단어의 의미를 수치화 하기 위한 방법이다.
한국 - 서울 + 도쿄 = 일본 / 박찬호 - 야구 + 축구 = 호나우두
신기하게도 단어가 가지고 있는 의미들을 가지고 연산을 하고 있는 것처럼 보인다. 이런 연산이 가능한 이유는 각 단어 벡터가 단어 벡터 간 유사도를 반영한 값을 가지고 있기 때문이다.
단어의 의미를 다차원 공간에 벡터화하는 방법을 사용하는데 이러한 표현을 분산 표현(distributed representation) 이라고 한다. 그리고 분산 표현을 이용하여 단어 간 의미적 유사성을 벡터화하는 작업을 워드 임베딩(embedding)이라 부르며 이렇게 표현된 벡터를 임베딩 벡터(embedding vector)라고 한다.
<학습 방식: CBOW(Continuous Bag of Words) & Skip-Gram>
1. CBOW
CBOW는 주변에 있는 단어들을 입력으로 중간에 있는 단어들을 예측하는 방법이다.

- 예문 : "The fat cat sat on the mat"
예를 들어서 갖고 있는 코퍼스에 위와 같은 예문이 있다고 하자. ['The', 'fat', 'cat', 'on', 'the', 'mat']으로부터 sat을 예측하는 것은 CBOW가 하는 일이다. 이때 예측해야하는 단어 sat을 중심 단어라고 하고, 예측에 사용되는 단어들을 주변 단어라고 한다.
중심 단어를 예측하기 위해서 앞, 뒤로 몇 개의 단어를 볼지를 결정해야 하는데 이 범위를 윈도우라고 한다. 예를 들어 윈도우 크기가 2이고, 예측하고자 하는 중심 단어가 sat이라고 한다면 앞의 두 단어인 fat와 cat, 그리고 뒤의 두 단어인 on, the를 입력으로 사용한다.
윈도우 크기가 n이라고 한다면, 실제 중심 단어를 예측하기 위해 참고하려고 하는 주변 단어의 개수는 2n개 이다.
윈도우 크기가 정해지면 윈도우를 옆으로 움직여서 주변 단어와 중심 단어의 선택을 변경해가며 학습을 위한 데이터 셋을 만드는데 이 방법을 슬라이딩 윈도우라고 한다. 위 그림은 CBOW를 위한 전체 데이터 셋을 보여준다.
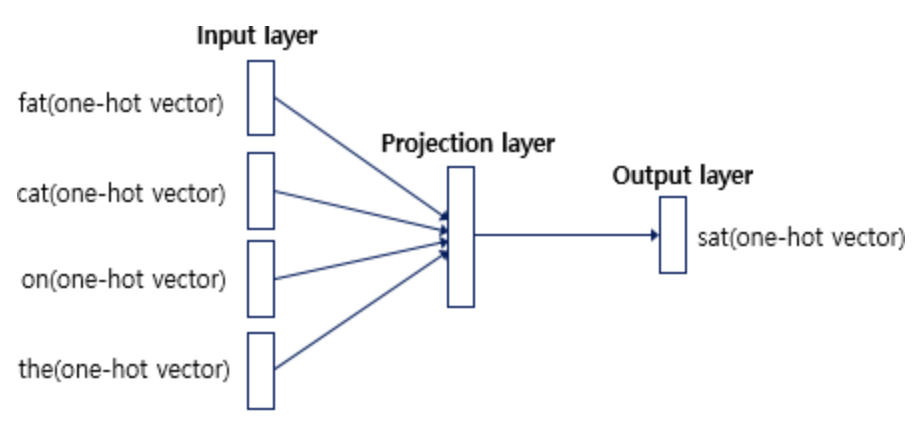
CBOW의 인공 신경망을 도식화한 것이다. 입력층(Input layer)의 입력으로서 앞, 뒤로 사용자가 정한 윈도우 크기 범위 안에 있는 주변 단어들의 원-핫 벡터가 들어가고, 출력층(Output layer)에서 예측하고자 하는 중간 단어의 원-핫 벡터가 레이블로 필요하다.
위 그림에서 알 수 있는 것은 Word2Vec은 은닉층이 다수인 딥 러닝(deep learning) 모델이 아니라 은닉층이 1개인 얕은 신경망(shallow neural network)이라는 것이다. 또한 Word2Vec의 은닉층은 일반적인 은닉층과는 달리 활성화 함수가 존재하지 않으며 룩업 테이블이라는 연산을 담당하는 층으로 투사층(projection layer)이라고 부르기도 한다.
CBOW의 동작 메커니즘을 더 자세히 설명한 것은 링크를 참고하면 되겠다. https://wikidocs.net/22660
2. Skip-Gram
Skip-Gram은 중간에 있는 단어들을 입력으로 주변 단어들을 예측하는 방법이다.


'딥러닝_실습' 카테고리의 다른 글
| L2. Face Detection (1) | 2024.05.02 |
|---|---|
| L1. Image Classification (0) | 2024.05.02 |
| 딥러닝 실습 (0) | 2024.04.30 |
