CS231n(9) CNN Architectures
CNN Architecture

9강은 최신 CNN 아키텍처에 대한 강의이다. 모두 imageNet 챌린지에서 우승하였다.
복습)

이미지를 입력으로 받아 stride = 1 인 5x5 필터를 통해 몇 개의 Conv Layer와 pooling layer를 거치고,
마지막으로 FC Layer를 통과한다. 간단한 모델이지만 필기체 숫자 인식에서 성공하여 우편번호(zip code) 인식에 사용되었다.
1) AlexNet
-최초의 거대한 convolutional neural network였다.
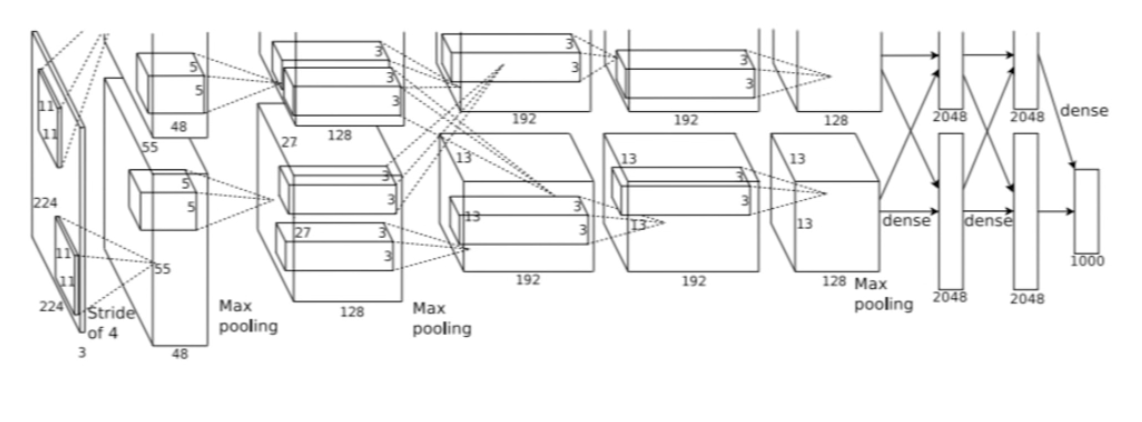

Input: 227 x 227 x3 images
FirstLayer(CONV1): 96개의 11x11 filters applied at stride 4
Q1) Output Volume?: (227-11)/4 + 1 =55
답) 55x55x96
Q2) the total number of parameters in this layer?
11x11x3x96 = 35K (3: input depth)
SecondLayer(POOL1): 3x3 filters applied at stride 2
Q3) Output Volume?: (55-3)/2+1 = 27
답) 27x27x96
Q4) the total number of parameters in this layer?
0 (왜냐 pooling layer는 parameter가 없다. 파라미터는 우리가 학습시키는 가중치이다. Conv Layer에는 학습할 수 있는 가중치가 있지만 pooling layer는 특정 지역에서 큰 값을 뽑아내기 때문에 학습시킬 파라미터가 없다.)

계산
INPUT : [227 x 227 x 3]
CONV1 : 96 11x11 filters at stride 4, pad 0 -> (227 - 11)/4 + 1 = 55 -> [55 x 55 x 96], p = (11x11x3)x96
MAX POOL1 : 3x3 filters at stride 2 -> (55 - 3)/2 + 1 = 27 -> [27 x 27 x 96], p=0
NORM1 : [27 x 27 x 96]
CONV2 : 256 5x5 filters at stride 1, pad 2 -> (27 + 2*2 - 5)/1 + 1 = 27 -> [27 x 27 x 256], p=(5x5x96)x256
MAX POOL2 : 3x3 filters at stride 2 -> (27 - 3)/2 + 1 = 13 -> [13 x 13 x 256], p=0
NORM2 : [13 x 13 x 256]
CONV3 : 384 3x3 filters at stride 1, pad 1 -> (13 + 2*1 - 3)/1 + 1 -> 13 -> [13 x 13 x 384], p=(3x3x256)x384
CONV4 : 384 3x3 filters at stride 1, pad 1 -> (13 + 2*1 - 3)/1 + 1 -> 13 -> [13 x 13 x 384], p=(3x3x384)x384
CONV5 : 256 3x3 filters at stride 1, pad 1 -> (13 + 2*1 - 3)/1 + 1 -> 13 -> [13 x 13 x 256], p=(3x3x384)x256
MAX POOL3 : 3x3 filters at stride 2 -> (13 -3)/2 + 1 = 6 -> [6 x 6 x 256], p=0
FC1 : p=4096
FC2 : p=4096
FC3 : p=1000
사전지식)
- Convolutional layer에서의 Feature Map 수: Convolutional 레이어에서는 주로 특정 GPU에서 계산된 Feature Map만 사용한다. (feature map: 입력 이미지에서 다양한 특징을 추출하기 위해 여러 개의 합성곱 레이어를 사용하는데 이러한 합성곱 레이어를 통해 생성된 출력을 말함) 이는 병렬 처리를 통해 연산 속도를 향상시키기 위함이다. 따라서 주어진 Convolutional 레이어에서는 특정 GPU에 의해 계산된 Feature Map만 사용되고, 이전 레이어의 모든 Depth가 사용되지 않는다. 따라서 48개의 Feature Map만 사용하는 것이다.
- FC Layer와 Convolutional 레이어 사이의 연결: FC Layer는 이전 계층의 전체 Feature Map과 연결된다. 이는 FC 레이어의 특성으로, 이전 레이어의 모든 뉴런과 연결되어 있으므로 전체 feature map과 연결되어 있다.

여길보면 모델이 두개로 나눠져서 서로 교차하고 있다. 그 당시 AlexNet을 GTX850으로 학습시켰는데, 이 GPU의 메모리는 3GB 뿐이었다. 전체 레이어를 하나의 GPU에 넣을 수 없어 네트워크를 GPU에 분산시켜 넣었다. 각 GPU가 모델의 뉴런과 Feature Map을 반씩 나눠 가진다. 그래서 첫 번째 레이어의 출력은 55 x 55 x 96이지만 각 GPU에서의 Depth는 48이다. (각각 48씩 총 96. 이 때 처음으로 GPU를 사용했다.)

AlexNet의 Conv 1,2,4,5 에서는 같은 GPU 내에 있는 Feature Map만 사용하기 때문에 48개의 Feature Map만 사용한다

Conv 3와 FC 6, 7, 8는 이전 계층의 "전체 Feature map"과 연결되어 있다. 이 레이어들에서는 GPU간 통신을 하므로 이전 입력 레이어의 전체 Depth를 전부 가져올 수 있기 때문이다.
ZFNet
-ZFNet은 AlexNet과 같은 레이어 수를 가지고 기존적인 구조가 같았다.
stride size, 필터 수 같은 하이퍼파라미터를 조절해서 AlexNet의 Error rate를 개선시켰다.
-2013년의 ImageNet Challenge의 승자이기도 했다.
VGGNet

1. 필터가 더 작아지고 network가 더 깊어졌다. 이전의 8개의 레이어에서 19개의 레이어와 19개의 레이어로 늘어났다.
2. 3 x 3 conv 를 유지했다.
( 3x3의 Conv layer는 7x7 conv layer와 동일한 effective receptive field를 갖는다.)
여기서 effective receptive field라 하면 filter가 한번에 볼 수 있는 입력의 영역이다
첫 번째 레이어의 Receptive Field는 3 x 3이다. 두 번째 레이어는 각 뉴런이 첫 번째 레이어 출력의 3 x 3 만큼 보고, 3 x 3 중에 각 사이드는 한 픽셀씩 더 볼 수 있다. 따라서 두번째 레이어는 실제로 5 x 5의 receptive filed를 가진다. 세 번째 레이어는 두 번째 레이어의 3 x 3 을 보게 되므로 결국 입력 레이어의 7 x 7을 보게 된다. 따라서 3 x 3 필터를 여러 개 쌓은 것은 하나의 7 x 7 필터를 사용하는 것과 같다.

따라서 3 x 3 필터를 여러 개 쌓은 것은 7 x 7 필터와 실질적으로 동일한 receptive field를 가지면서 더 깊은 레이어를 쌓을 수 있다.
더 깊게 쌓기 때문에 Non-Linearity를 더 추가할 수 있고 파라미터 수도 적어진다.
여기서 질문) 깊은 레이어를 쌓는 게 왜 중요할까? 왜 non-linerarity를 추가하려고 하는 거고 파라미터 수도 적게 하는 걸까?
-깊은 레이어: 깊은 층을 가진 네트워크는 더 다양한 특징을 학습할 수 있고 이를 통해 더 정교한 패턴 및 추상적인 개념을 학습할 수 있다.
-Non-linearity의 추가: 깊은 네트워크는 많은 비선형 활성화 함수를 포함하므로 더 강력한 표현력을 제공한다. 비선형 활성화 함수(예: ReLU, 시그모이드)는 네트워크에 비선형성을 주어 복잡한 함수를 학습할 수 있게 한다.
-파라미터 수 감소: 의 공유: 이는 네트워크의 효율성을 높이고, 과적합을 방지한다. 깊은 네트워크에서는 파라미터를 공유함으로서 동일한 특징을 여러 위치에서 사용하여 모델의 파라미터 수를 줄인다.
3. 7.3%의 top 5 error(5개 중 답이 있는 경우) 를 달성했다.
Q1) 3 x 3 필터를 3개 쌓은 것의 전체 파라미터의 갯수는?
3 x 3 필터의 파라미터의 수: 3 x 3 = 9
depth C: 3 x 3 x C
출력 Feature Map(= Depth = C) : 3 x 3 x C x
레이어를 3개 쌓음: 3 x (3 x 3 x C x C) =
위와 같은 방식으로 계산하면 7 x 7 필터의 파라미터의 갯수는 7 x 7 x C x C = 49이다(레이어 1개).
따라서 3 x 3필터를 3개 쌓은 것이 7 x 7필터보다 파라미터의 수가 더 적다.
GoogLeNet

-22 layers (깊은 네트워크 + computational 효율)
-efficient inception module
-no FC layers
-only 5 million parameters
-6.7% top 5 errors
Inception Module
Deep neural network의 성능을 향상시키려면 모델 size를 늘리면 된다 -> 그러나 이는 overfitting과 계산 자원 증가의 문제가 있다.
==> fully connection architect 말고 sparsely connected architect(지난 Output의 연관관계가 높으면 연결하되 나머지는 연결하지 않는다)는 어떨까?
==> 오늘날 컴퓨팅 인프라는 sparse 데이터 구조에 대한 수치 계산에 비효율 적이다
==> inception module 은 어떨까? 하여 등장하였다.

1. Optimal local construction을 찾고 이걸 공간적으로 반복하면 어떨까
- 이미지에서 local끼리는 correlation이 크니까 1x1 filter을 이용하자
- 멀리 떨어진 correlation 있는 것들의 cluster를 3x3, 5x5 filter으로 나타내자
- 3x3 max pooling은 이 당시에 이게 너무 잘되었어서 이것도 넣어보자
이렇게 아이디어를 가지고 이들을 병렬적으로 더해서 만들어보자라고 한 것이 naive version의 Inception module이다.
==> 그러나 풀링층과 conv층 출력을 합치는 것은 출력의 수가 늘어날 수밖에 없었고 최적의 희소성 구조를 커버할 수는 있었지만 매우 비효율적이었다.

1x1 conv에 128개, 3x3 conv에 192개, 5x5 conv에 96개 필터가 있고 Input으로 28x28x256이 있다고 하자
Q1) 1x1 conv의 output size는 무엇일까? 답) 28x28x128
3x3 conv는 28x28x192이고 5x5는 28x28x96이고 3x3 pool은 28x28x256일 것이다.
Q2) filter concatenation 후의 output size는?
28x28x(128+192+96+256) = 28x28x672이다.
spatial dimension은 동일한 채 depth만 커졌다.

pooling layer도 문제가 된다. 모든 feature depth를 가져와서 total depth이 더 늘어난다.
==> 해결책: bottleneck layers that use 1x1 convolutions
1x1 convolutions
:preserves spatial dimensions and reduces depth

2. 연산해야 하는 노드들을 1x1 filter로 줄여주고 계산량이 높은 convolution들을 계산하자
맨 오른쪽의 maxpooling은 채널 수를 조절할 수 있는 방법이 없어서 나중에 조절해주기 위함이다. 1x1 convolution은 채널 수를 줄여주는 dimension reduction의 역할을 해준다.
이 방법은 계산 자원의 활용이 개선되어 계산상의 어려움에 빠지지 않고 단계 수를 늘릴 수 있게 되었다.
동일한 입력을 받는 여러개의 필터들이 병렬로 존재하고, 각각의 출력값들을 depth 방향으로 합치고, 이 합쳐진 하나의 tensor을 다음 레이어로 전달하는 방식이다.


=> totla num of operations가 줄었다.


그리고 googLeNet같은 경우 auxiliary classifier가 존재한다.
네모 친 미니 네트워크들에서도 loss를 계산하는데, 이는 전체네트워크가 깊기때문에 그레디언트 값이 점점 작아져 0이 되는 것을 방지하여 중간 레이어들의 학습을 도와주는 역할을 한다.
-> 총 22 layers with weights
ResNet
Q1) plain한 convolutional neural network에 layer를 계속 쌓으면 어떻게 될까?

56 layer이 20 layer보다 test error가 많이 난다.
더 깊은 모델을 세울 때 optimization에 문제가 있다고 생각한 것이다.
따라서 깊이가 얕은 모델과 그 모델을 그대로 가져와서 깊이를 더 깊게 만드는데 깊이를 더 깊게 만들때 추가 layer들은 identity mapping을 해준다.( 입력값이 들어오면 그대로 출력값으로 나가게끔 해준다 )
이렇게 해주면 모델이 깊을 때 최소한 더 shallow한 모델의 성능만큼은 나오지 않을까?라는 생각이 든다.
=-> 이렇게 resNet이 등장하였다.

-152 layers for imageNet
-3.57 % top 5 error

해결책: 원하는 기본 매핑을 직접 맞추려고 하지 않고 네트워크 계층을 사용하여 잔차(관측값에서 얻어진 가장 확실한 값과 이론값의 차) 매핑을 맞춘다.
H(x) = F(x) + x 이다. 기본 출력 값 F(x)에 identity mapping으로 입력값인 x를 더해준다.
H(x)를 얻기는 어려우니 어떤걸 더하고 빼야하는지 보기 위해 F(x)를 H(x)-x로 보자.
입력 값을 수정한다는 의미로 받아들일 수 도 있다: F(x) = H(x) - x이고 변화량인 F(x)를 residual이라고 표현할 수 있다.
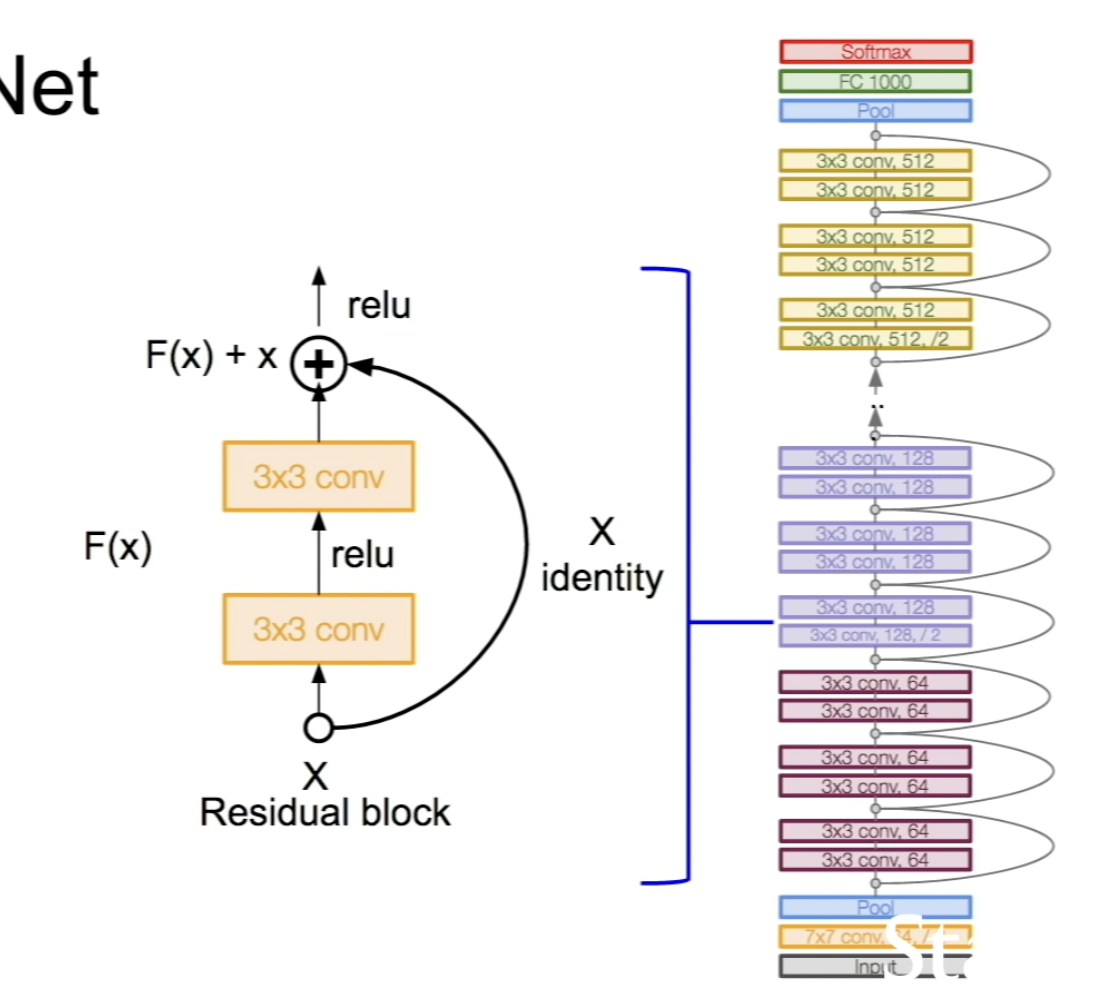
-ResNet은 기본적으로 VGG-19를 뼈대로 ConV층을 추가해 layer를 깊게 만들었다.
-3x3 ConV layer를 2개씩 쌓고 residual block을 끼워 주는데, 주기적으로 필터를 2배씩 늘리고 stride를 2로 두어서 다운 샘플링해주었다.
-모델의 시작은 ConV층으로 시작해서, 모델의 마지막에는 FC층이 없고, global average pooling layer을 이용했다.
-마지막은 1000 카테고리 이미지 분류를 위한 FC층만 있다.


-50 layer부터는 파라미터가 급격하게 많아져서 bottleneck을 이용한다.
-28x28x256을 넣으면 1x1 conv을 통해 28x28x64를 얻고 3x3 conv와 또 1x1 conv를 거쳐서 256이 된다.


Inception-V4: Resnet + Inception
VGG: highest memory, most operations (least efficient)
GoogLeNet: most efficient (low memory usage)
AlexNet: Smaller compute, still memory heavy, lower accuracy
ResNet: model에 따라 moderate efficiency, highest accuracy
Other Architecture (good to know)
1) NiN

각 conv layer안에 Multi layer perceptron(FC)을 쌓아서 네트워크 안에 작은 네트워크를 만드는 방식.
FC layer, 즉 1x1 conv layer을 사용해서 abstract features을 더 잘 뽑을 수 있도록 하고자 함.
googlenet, resnet보다 먼저 보틀넥의 개념 정립
2) ResNet block 향상

ResNet Block 디자인을 improve 했다.
direct path를 늘려서 forward, backprop이 더 잘 될 수 있도록 설계
- Wide residual 네트워크

사실 resnet에서 depth가 아닌 residual이 중요하다고 주장했다.
residual block의 conv layer 필터를 더 많이 추가해서 더 넓게 만들었다.
각 레이어가 넓어져서 50레이어만 있어도 152 레이어의 기존 성능보다 좋다.
filter의 width를 늘리면 병렬화가 더 잘되어서 계산 효율이 증가해서 좋다.
- aggregated residual for deep neural networks

residual block 내에 얇지만 다중 병렬 경로를 추가하였다. 마찬가지로 width늘리기
-ResNet + Inception

네트워크가 깊어질수록 Vanishing gradient 문제가 발생한다.
train time에 일부 네트워크를 골라서 identity connection으로 만든다.
shorter network가 되어 그래디언트가 더 잘 전달될 수 있다.
Dropout과 유사하고 test time에는 full deep network 사용한다.
=-> ResNet말고 다른 architecture은 없을까?
FractalNet

-no redisual representation
-transitioning from shallow to deep networks
DenseNet

-connection이 dense 해서 alleviates vanishing gradient
SqueezeNet

-fire modules