지난시간)
- gradient flow를 적절히 manage해야 한다. 이를 위해 Densenet과 Fractalnet이 등장했다.
- parameter: 모델이 학습하는 가중치(weight)와 편향(bias)을 가리킨다. 이들은 입력 이미지를 특정 클래스로 분류하거나 원하는 작업을 수행하는 데 사용된다. 각 계층(layer)에는 여러 개의 필터(filter)가 있고, 이러한 필터는 입력 이미지의 특징을 감지하기 위해 사용된다. 예를 들어 CNN 모델에서 첫 번째 합성곱 계층에서는 필터마다 가중치와 하나의 편향이 있다. 이 가중치와 편향은 입력 이미지와 필터를 합성곱하여 특징 맵(feature map)을 생성하는 데 사용된다.
Recurrent Neural Networks

- network가 handle할 수 있는 input과 output의 data type을 조절할 수 있다.
일반적으로 신경망들은 one to one 모양이다. RNN에서는 이외에도 다양한 type이 있다.
one to many같은 경우 input은 image같은 fixed size인데 output은 caption 같은 sequence of words를 출력할 수도 있다.
many to one은 piece of text를 input 받아서 positive냐 negative냐를 출력할 수도 있고
many to many는 video의 여러 picture을 보고 어떤 action이 일어나고 있는지가 도출될 수도 있다.
따라서 RNN는 handling variable sized sequence data to capture differenct setups in the model이다. 타임 스텝에서의 예측은 (현재 프레임 + 지나간 프레임들)에 대한 함수로 이루어지게 되는 것이다.
-sequential processing of non-sequence data
숫자 image를 보고 한번에 결정을 내리는게 아니라 image를 살펴보고 다양한 부분을 glimpse하고 어떤 숫자인지 결정을 내리는 것이다.
RNN 식

RNN은 내부에 hidden state가 있다. 이 hidden state는 RNN이 새로운 input을 입력받을 때마다 update 된다.
함수 f는 이전 상태인 ht-1과 현재 상태의 xt을 입력받는다. 이후 next hidden state인 ht를 출력해서 update 한다. output을 내고 싶으면 fully-connexted layers를 추가하면 된다. 그리고 항상 같은 f와 w를 사용한다.

vanilla RNN 식
Many to Many

매번 다른 h와 x가 입력되지만 동일한 W가 모든 과정에서 사용된다. 이 RNN 모델의 backprop을 위한 행렬 W의 gradient를 구하려면 각 스텝에서 W에 대한 gradient를 전부 계산한 후 이를 더해주면 된다.
Loss도 보면 스텝마다 output이 나오기 때문에 각각의 output에서의 loss도 계산할 수 있다. 최종 loss는 모든 개별 loss들의 평균이 된다.
Many to One

이 경우 네트워크의 최종 state에서만 output y가 나온다.
One To Many

이 경우는 fixed size input에서 variably sized output이 나오는 경우이므로 다음과 같은 그림이 나온다.
input은 모델의 initial hidden state를 초기화하는 용도로 쓰인다.
many-to-one + one-to-many

이것은 machine translation에 사용할 수 있다. (machine translation: 인간이 사용하는 자연 언어를 컴퓨터를 사용하여 다른 언어로 번역하는 일을 말한다.) many-to-one(encode)과 one-to-many(decode) 모델의 결합이다. 여기서는 가변 입력을 받을 수 있다. 그리고 마지막 hidden state를 통해서 전체를 요약해 하나의 출력으로 요약한다.
출력 한개가 다시 one to many 모델의 input으로 들어가고 one to many처럼 가변 출력을 가진다.
computatioanl graph를 unroll 하면서 training한다고 생각하면 된다. (loss를 계산하고, backprop를 하고..)

h를 input하면 hidden layer를 지나서 output layer에서 각각의 벡터에 대한 score를 얻는다. test time에서는 이 score를 다음 글자를 선택하는 데 이용한다. score를 softmax함수를 이용해서 확률분포로 표현한다. 가장 높은 스코어가 아닌 확률분포로 굳이 샘플링을 하는 이유는 모델에서 다양성을 얻기 위함이다.
그림을 보면 1번째에서 hello니까 e가 나오기를 원하는데 output layer 수치로만 보면 4.1이므로 o가 나온다. RNN 모델에서는 다음 학습시에 2.2의 확률은 높이고, 나머지는 확률을 낮추도록 parameter(weight)를 미세하게 조정할 것이다. (RNN은 미분함수로 구성되어 있어, backpropagation 알고리즘을 통해서 어떤 방향이 정답의 확률을 높이는지 찾아갈 수 있다). 이렇게 paramter가 업데이트 된 후에 동일한 input이 입력되면 좀 더 정답의 확률이 높아지게 될 것이다. (2.2 --> 2.5)

- T: time step, sequence의 갯수
-input layer == 4개 (h,e,l,l)
-hidden layer == 4개 - X: input 값, 입력받은 문자열
-각 time step마다 입력되는 문자열 (character or word)
-여기서는 h,e,l,l - S: hidden state
-이전 state와 현재 input값의 계산 결과
-함수 f는 보통 tanh or ReLU 사용
-첫번째 S=0으로 설장 - O: output layer, 각 time step에서 출력값 (다음에 나타날 단어)
-예측할 character의 갯수만큼의 배열로 구성됨
-예제에서는 hello == 4개의 단어로 구성됨 h,e,l,o
-O에서는 각 단어별로 정답일 확률을 수치로 저장함
-Ot=softmax(tanh(..))
-실제 저장되는 값은 [1.0, 2.2, -3.0, 4.1]임 - Weight: 다음 단어를 예측하기 위해 training을 통해 찾아야할 vector 값
-초기값은 전부 랜덤하게 지정(0에 가깝게)
-Wxh(U): input layer -> hidden later에 적용할 가중치
-Whh(W): hidden layer간의 가중치
-Why(V): hidden layer -> output layer에 적용할 가중치
=> 각 time step별로 Weight는 동일하다
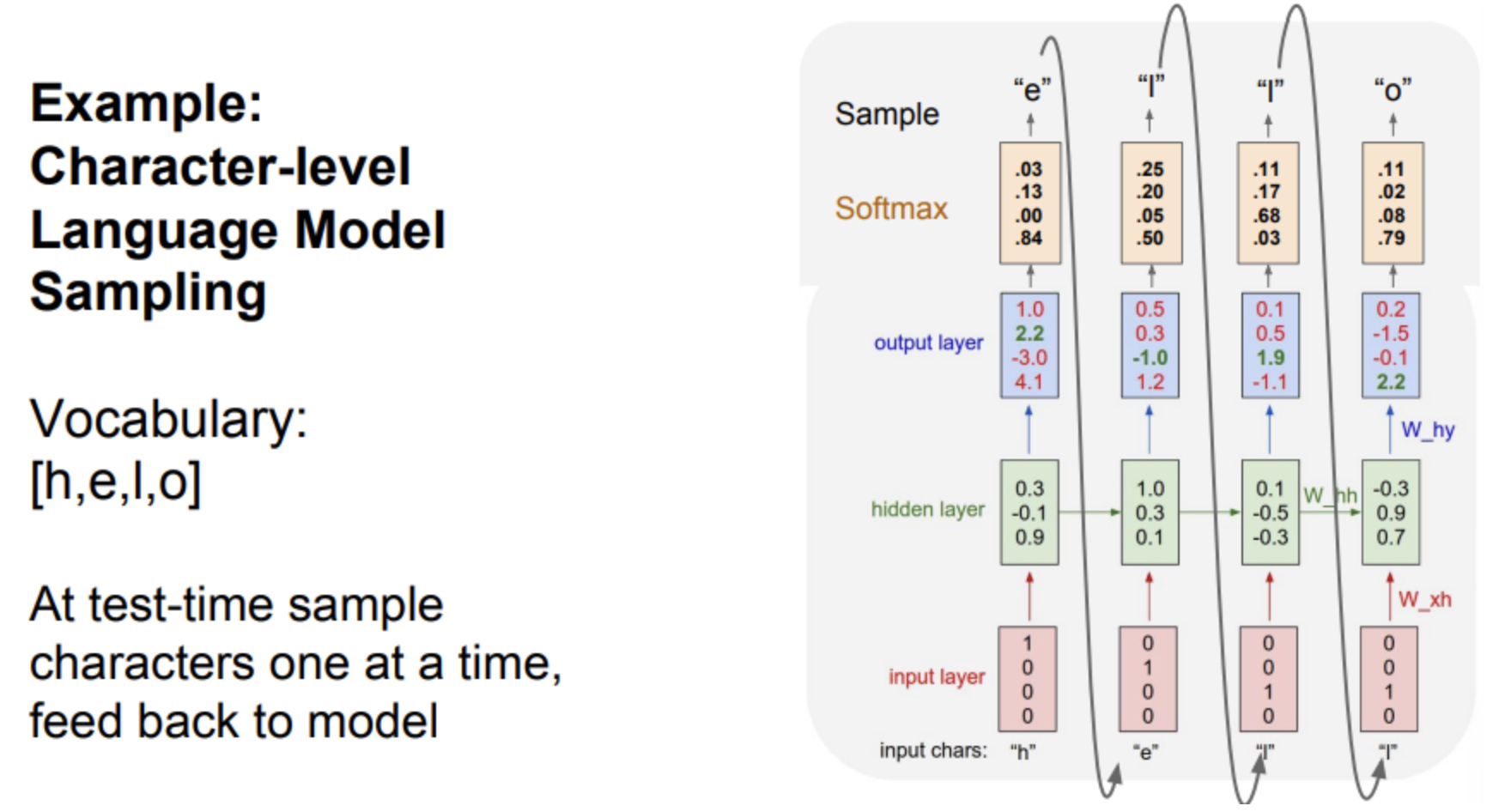
이후 test time에는 이 model을 바탕으로 새로운 단어를 합성할 것이다.
이 학습 모델을 잘 활용하기 위해서 모델로부터 sampling하는 것인데 train할 때 모델이 봤을 법한 문장들은 모델이 스스로 생성하도록 하는 것이다. e가 새로 입력되고 l이 나오고… 이를 반복한다. 확률 분포가 훈련된 model을 통해 새로운 sequence를 합성하는 것이다.

TensorFlow 코드는 다음과 같다.
참고:https://m.blog.naver.com/freepsw/220919260725
Backpropagation through time
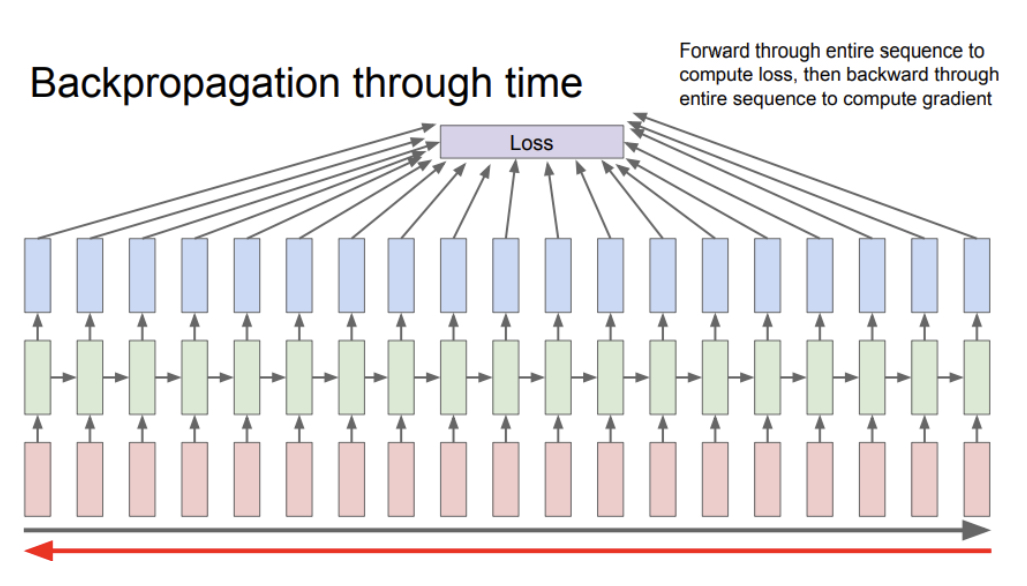
backpropagation through time은 매 스텝마다 출력값의 loss를 계산해서 최종적으로 loss를 얻는 것이다. 이는 정방향이든 역방향이든 전체 sequence를 가지고 loss를 계산하기 때문에 sequence가 길어지면 문제가 생긴다

따라서 truncated backprop를 통해 근사시키는 방법이 있다. train할 때 한 step(batch)을 일정 단위로 자르고 단계를 진행하기 때문에 시간이 오래 걸린다. hidden-state를 계속 유지한 채 반복하지만 backprop은 현재 step만큼만 진행한다.
첫번째 batch에서 계산한 hidden state가 있다. gradient step을 계산할 때 두번째 batch를 통해 backprop할 것이다.
거대한 data set에서 gradient를 계산하는 것은 비싸다. 따라서 mini batch를 가져와서 gradient를 계산하는 것이다.
The SONNETS
:셰익스피어의 작품들을 RNN으로 학습시켰다.
min-char-rnn.py gist: 112 lines of Python
andrea가 만든 코드로 RNN 전체 과정을 구현하였다.
https://gist.github.com/karpathy/d4dee566867f8291f086
Searching for interpretable cells
RNN을 특정 데이터셋으로 학습시키고 hidden state를 하나 뽑아서 어떤 값이 들어 있는지를 보는 것이다.

대부분의 hidden state는 아무 의미 없는 패턴을 지닌다. 그래서 vector를 하나 뽑은 다음, 이 시퀀스를 다시 forward 시켰다. 여기서 각각의 색은 시퀀스를 읽는 동안에 앞에서 뽑은 hidden vector 값을 의미한다.

여기서는 quote(따옴표)를 찾는 벡터를 발견했다. 처음에는 off 상태(파란색이 off)였다가 따옴표를 만나면 값이 켜지고 다음 따옴표를 만나면 꺼진다. 이런식으로 모델이 다음 문자를 예측하도록 학습시켰지만 모델은 더 유용한 것을 학습하게 된다.
이외에도 줄바꿈을 하기 위해 현재 줄의 단어의 갯수를 세는 것도 있다. 한 줄이 처음엔 파란색으로 시작했다가 줄이 점점 길어지면 빨간색으로 변한다. 그리고 줄을 바꾸면 다시 파란색이 된다.
Image Captioning

CNN과 RNN이 결합된 기술이 Image Captioning이다. CNN으로 사진을 넣으면 RNN에서 다양한 단어가 output으로 나온다.

CNN은 이미지 정보가 들어있는 vector를 출력한다. 이 vector는 RNN의 첫 step에서의 입력으로 들어간다. 그러면 RNN은 caption에 사용할 문자들을 생성한다.
과정을 보면 먼저, input 이미지를 받아서 CNN의 입력으로 넣는다. 이때 softmax score를 사용하지 않고 직전의 vector의 출력 (FC-4096)으로 한다. 위의 그림에서 식을 보면 이전까지의 RNN 모델은 현재 step의 input 값과 이전 step의 hidden state 값을 입력으로 받았고 이것으로 다음 hidden state를 얻었다. 하지만 이제는 이미지 정보도 추가한다. 세번째 가중치 행렬을 추가하는 것이다. 다음 hidden state를 계산할 때마다 이 이미지 정보를 추가하는 것이다. 이렇게 해서 y0라는 sampling된 단어가 나오면 다음 스텝의 입력으로 들어간다.

이걸 반복하고 모든 스텝이 종료되면 한 문장이 나오게 된다. <END> 가 샘플링되면 더이상 단어를 생성하지 않고 이미지에 대한 caption이 완성된 것이다.
Attention
image captioning에서 더 발전한 모델이다. 이 모델은 caption을 생성할 때 이미지의 다양한 부분을 집중해서 볼 수 있다.

간단히 말하면 하나의 벡터를 만들기 보다 grids of vector(각각의 벡터가 갖고 있는 공간정보)를 만든다. 매 스텝 샘플링을 할 때, 모델이 이미지에서 보고 싶은 위치에 대한 분포도 만든다. 이미지의 각 위치에 대한 분포는 train time에 모델이 어느 위치를 봐야하는 지에 대한 attention(a1)이라고 할 수 있다.
과정을 보면 h0는 이미지의 위치에 대한 분포를 계산하고 그 output인 a1이 다시 feature LxD와 연산해서 z1을 생성한다. z1은 다시 다음 스텝의 input으로 들어가고 2개의 출력이 나온다. 하나는 단어들의 분포이고 하나는 이미지 위치에 대한 분포이다. 계속하면 step마다 output이 2개가 나온다.

여기서 soft attention은 모든 특징과 weight를 보고 hard attention는 attention의 위치에 더 집중을 한다.
Multilayer RNNS

지금까지는 hidden state가 1개였지만 지금부터는 hidden state가 여러개인 모델이다. 입력이 들어가서 첫번째 hidden states를 만들고 이는 다른 RNN layer의 input으로 들어간다. 이렇게 해서 2-3 layer의 RNN이 만들어질 것이다.(많이 깊어지진 않는다).
이 vanilla RNN cell이 train할 때 어떤게 발생하는지 보자 input으로 xt와 ht-1이 들어와서 tanh에 넣고 squash하면 다음 hidden state가 나오게 된다. 아래 그림에서 오른쪽과 같은 계산이다.

근데 gradient를 계산하기 위해 backward pass할때 어떤 일이 일어날까? h_t에 대한 loss의 미분 값을 얻게 된다. 그 다음 loss에 대한 h_t-1의 미분값을 계산하게 된다. 이렇게 backward pass의 전체과정은 빨간색 순서대로 진행된다.
h0에 대한 gradient를 구하려고 하면 모든 RNN cell을 거치게 되고 통과할 때마다 가중치 행렬 W가 관여하게 된다. 따라서 곱해지는 값이 1보다 커서 explode하지 않고 1보다 작아서 0이 되지 않으려면 곱해지는 값이 1이 되어야 한다.
1보다 크면 exploding gradients하기 때문에 gradient clipping이라는 방법을 도입했다.

Long Short Term Memory

1보다 작으면 vanishing gradients하기 때문에 도입되었다.
Vanilla RNN과 달리 LSTM에는 2개의 hidden state가 있는데 ct(cell state)와 ht가 그것이다. ct는 LSTM 내부에 있고 안 드러난다
i: cell 에서의 입력 xt에 대한 가중치, f: 이전 스텝의 cell을 얼마나 잊을지
o: cell state를 얼마나 밖으로 출력할 것인지, g: input cell을 얼마나 포함시킬지
i,f,o,는 sigmoid를 써서 0에서 1사이이고 g는 tanh 써서 1에서 -1 사이이다.

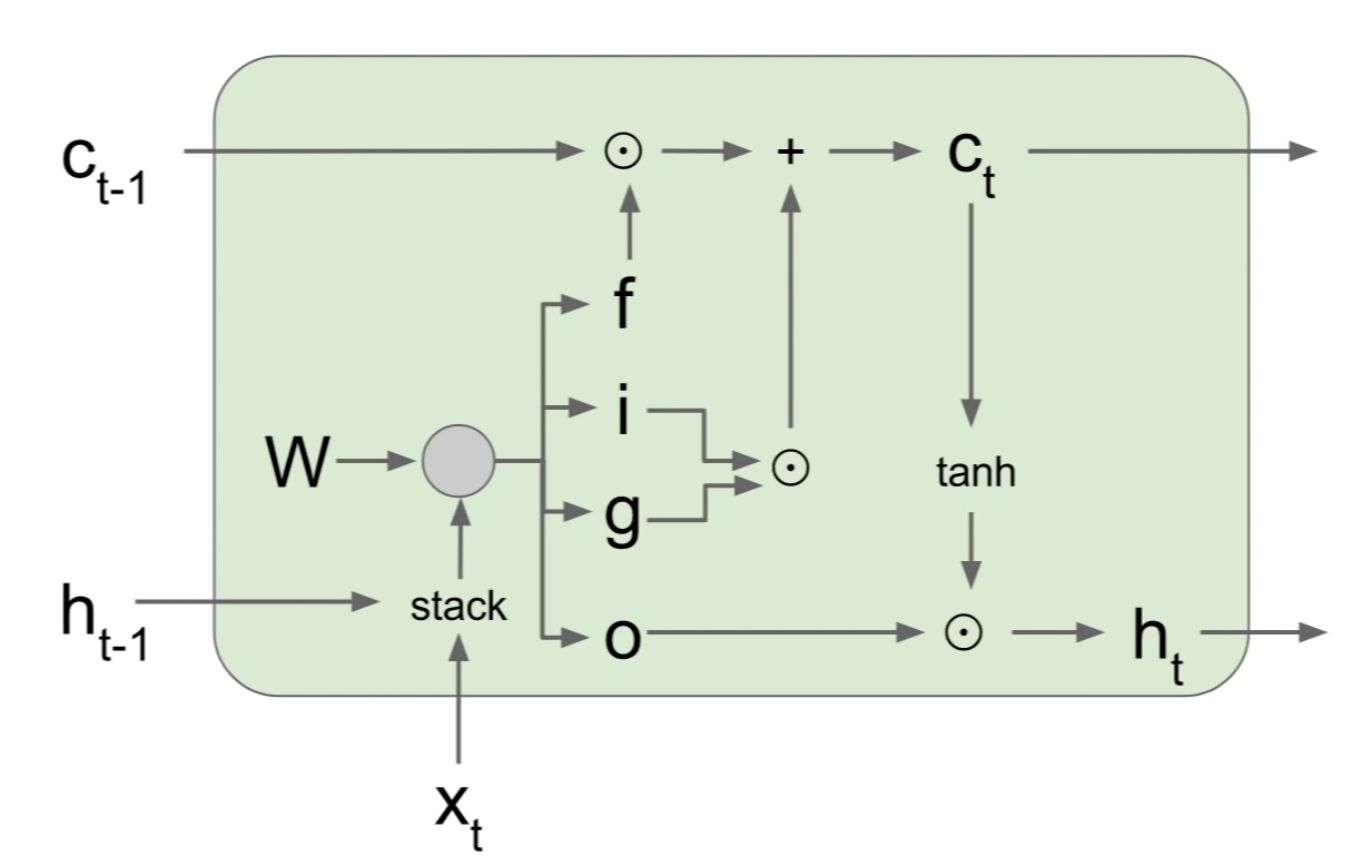
backward pass 할때 LSTM Cell에는 어떤일이 일어날까?
vanilla에서는 W가 계속 곱해졌다. 하지만 LSTM은 forget gate가 스텝마다 계속 변해서 이러한 문제를 더 쉽게 해결할 수 있다.
forget gate는 sigmoid를 거치기 때문에 결과가 0과 1사이일 것이다.
그리고 vanilla rnn의 backward pass에서는 매 스텝마다 gradient가 tanh를 거쳐야 했다. 그러나 LSTM은 h_t를 c_0까지 backprob하려고 할 때 tanh를 한번만 거치면 된다.

'CS231n' 카테고리의 다른 글
| Assignment 1-1 (KNN) (0) | 2024.03.18 |
|---|---|
| Assignment Python Tutorial (1) | 2024.03.14 |
| CS231n(9) CNN Architectures (1) | 2024.03.12 |
| C231n(8) DeepLearning Software (0) | 2024.03.10 |
| CS231n(7) Training Neural Networks II (3) | 2024.03.08 |



