지난시간 요약)
-optimization을 위한 fancier한 algorithm들에 대해 배움 ex) SGD+Momentum, Nesterov, RMSProp, Adam ...
-Regularization ex) dropout: network를 무작위로 0으로 설정한 다음 테스트 시 뒤쪽의 noise를 무시한다
-Transfer Learning: 일부 데이터 세트에 대해 사전 훈련된 대규모 network를 다운로드하고 자신의 문제에 맞게 미세조정하는 방법
DeepLearning Software
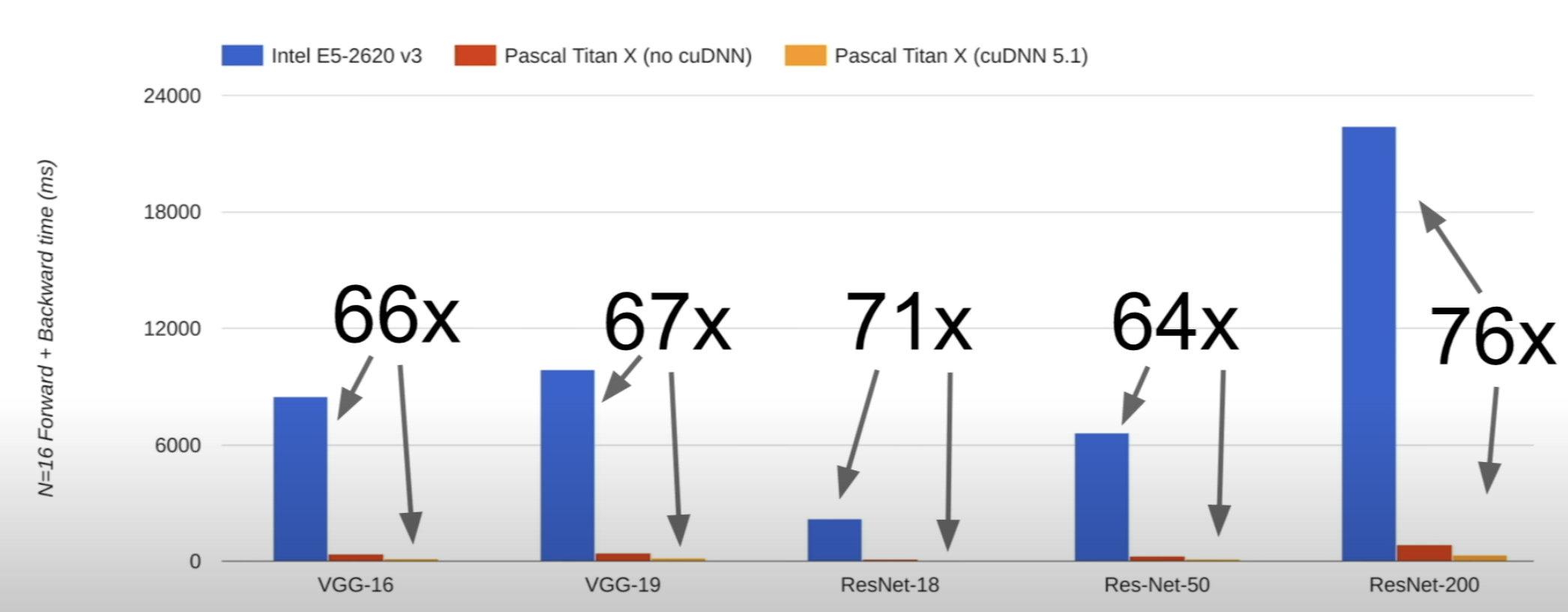
CPU VS GPU
CPU: Central Processing Unit ; 코어가 4-6개 있고 하이퍼스레딩 기술을 사용하면 물리적으로 8-20개 스레드를 사용한다
GPU: Graphics Processing Unit ; 수천개의 코어가 있지만 속도가 느리다. 대규모 병렬(행렬) 문제에 더 나은 처리량을 갖는다.
NVIDIA가 AMD보다 딥러닝에 사용하기 좋다. NVIDIA는 GPU에 매우 최적화된 일반적인 계산 기본 요소를 구현하는 많은 라이브러리를 출시했다.
cuBLAS 라이브러리: 행렬연산 cuDNN 라이브러리: 컨볼루션, 정방향 및 역방향 전달, batch normalization, 순환 network, 딥러닝


실제로 CPU와 GPU는 물리적으로도 분리돼있다. GPU가 코어개수가 많은만큼 크기도 큰데, 실제로 GPU로 학습을 할 때 둘이 분리되어 있음으로 생기는 문제가 있다. 실제 Model과 가중치는 GPU 개별 RAM에 저장돼있고, Train data는 컴퓨터저장장치(HHD, SSD등)에 저장돼있다는 점이다. Train data는 굉장히 큰 데이터이기 때문에 GPU에서 훈련을 반복수행할 때 데이터를 복사해서 이동하는 큰 작업이 반복된다. 이를 해결하기 위한 방법이 3가지 있다.
① 데이터셋이 작다면 RAM에 미리 올려놓기
② HDD보다 SSD를 쓰면 데이터 읽는속도가 더 빠르다.
③ CPU 멀티스레딩을 이용해 데이터를 RAM에 미리 올려놓고(pre-fetching) GPU로 보내면 더 빨리 보내짐
-Numpy vs TensorFlow vs Pytorch

Numpy :
import numpy as np
np.random.seed(0)
N,D = 3,4
x=np.random.randn(N, D)
y=np.random.randn(N, D)
z=np.random.randn(N, D)
TensorFlow:
x = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
z = tf.placeholder(tf.float32)
#gradient 계산
grad_x, grad_y, grad_z = tf.gradients(c, {x,y,x})
#cpu와 gpu 간에 계산 전환
with tf.device('/cpu:0') 또는 with tf.device('/gpu:0')
Pytorch:
x=Variable(torch.randn(N, D), requires_grad=True)
y=Variable(torch.randn(N, D), requires_grad=True)
z=Variable(torch.randn(N, D), requires_grad=True)
#gpu로 실행: z=Variable(torch.randn(N, D).cuda(), requires_grad=True)
#Forward Pass
a=x*y
b=a+z
c=torch.sum(b)
#Pytorch로 gradient 계산
c.backward()
print(x.grad.data)
print(y.grad.data)
print(z.grad.data)
<비교>
1. Computational Graphs
- Numpy를 이용
- 단점
(1) Backward pass연산은 단계적으로 계산해야함
(2) GPU연산을 이용하지 못함
=> 따라서 프레임워크를 사용하자!
2. TensorFlow
- Forward pass는 Numpy와 비슷해보이지만, Backward pass를 한번에 해버리는 프레임워크
grad_x, grad_y, grad_z = tf.gradients(c, [x, y, z])
- GPU에서 연산하라는 코드: with tf.device ('/gpu:0')
3. PyTorch
- 한줄로 backward pass 가능
- .cuda() : GPU사용
TensorFlow Neural Network
: 랜덤데이터로 2 layer ReLU network의 L2 loss를 구하는 예시로 기본 구조를 설명한다
반복할 경우:
<문제>: 정방향 전달에서 이 그래프를 실행할 때마다 CPU에 저장한 graph structure에서 weight 데이터를 복사해 GPU에서 연산하고 다시 CPU로 출력하려면 계산이 무겁다
따라서 cpu 메모리와 gpu 메모리 간에 데이터를 복사하는 비용이 든다.
<해결>
1. weight를 placeholder가 아닌 tf.Variable에 저장한다.
2. weight 업데이트 또한 computational graph 안에서 연산되도록 해준다.
3. x, y만 데이터를 넣어주고 코드를 실행한다 (w1, w2 빼고)
=> 하지만 실제로 실행해보면 loss가 줄어들지 않는 문제가 발생한다. 왜일까?
: sess.run()에서 loss만 계산해달라고 했으니까 loss만 계산하고 w update는 안했다.
=> 따라서 updates = tf.group(new_w1, new_w2) 를 추가한다.
: 근데 여기서도 이 new_w1, w2가 큰 tensor라면 아까처럼 tensorflow 연산 밖에서 update를 가져왔다가 GPU연산을 하고 다시 밖으로 돌려보내는 큰 연산이 수행된다.
그래서 tf.group()을 사용한다.
group()는 여러 연산을 한번에 수행해주는 dummy node와 같은 역할을 하는데, 실제로 값을 반환하지는 않고 none을 반환한다. 하지만 loss를 계산하는데 update값들이 필요하기 때문에 실제 계산을 하는 부분인 tf.Session()에 꼭 필요한 부분이다.
4. Optimizer

근데 이렇게 tf.group을 이용하는 거보다 Optimizer를 사용해주는 게 좋다.
loss가 최소가되도록 variable들을 조절해주는 역할인데, 대표적으로 경사하강법 optimizer가 있다.
learning rate만 정해주면 알아서 loss계산에 필요한 weight 업데이트도 해주고 알아서 다해준다.
w1와 w2가 기본적으로 훈련 가능으로 표시된다는 것을 인식하므로 내부적으로 w1 및 w2에 대한 손실 기울기를 계산하는 그래프에 노드를 추가하고 업데이트 작업을 수행하고 할당한다.


Pytorch
: 3가지 추상화 계층이 있다.
tensor : 다차원배열인데 GPU에서 run 될 수있도록 하는 일종의 numpy 배열이다.
variable : computational graph의 하나의 노드라고 생각하면 된다. data와 gradient를 저장한다.
module : neural network의 layer라고 생각하자 state나 learnable weights를 저장한다.
TensorFlow vs pytorch
tensor은 numpy array이고 variable은 Tensor, Variable, Placeholder이고 module은 tf.layers, TFSlime, TFLearn...
pytorch와 tensorflow에 큰 차이는 graph가 dynamic 하다는 것이다.
tensorflow (sataic computational graph)는 그래프를 명시적으로 구성하고 그 다음 실행하는 반면
pytorch(dynamic computational graph)는 forward pass 할 때 마다 그래프를 다시 구성한다.
즉 training 할때마다 새로운 그래프를 만들기 때문에 코드를 깔끔하게 구성할 수 있다. optimizer을 이용해
learning rate 또한 쉽게 설정 가능하다.

GPU에서 작동시키기 위해 cuda datatype로 tensor 가져오기 : dtpye = torch.cuda.FloatTensor
Pytorch Tensors: numpy + GPU 라고 생각하기

- x.data는 Tensor이고, x.grad는 computational graph에서 tensor를 이용해 계산한 gradient이다.
그리고 x.grad.data는 그 gradients들을 담은 Tensor이다.
- Variable과 Tensor는 동일한 API 를 갖는다. 따라서 Tensor를 Variable로 바꾸고 그대로 코드를 실행해도 실행된다.
단, Computational graph를 그릴 때만은 Variable 타입으로 해줘야 한다.
- requires_grad : True일때 해당 데이터에 대한 gradient를 구하겠다는 것이다.
실제 x와 y에 대한 경사하강법을 진행하는 것이 아닌, weight에 대한 경사하강법을 진행하므로 파란박스에 True로 표시된 것을 볼 수 있다.
-loss.backward()를 호출하면 모든 gradient가 표시된다
-현재 w1.grad.data에 있는 gradient로 가중치에 대한 gradient update를 한다.

PyTorch는 자동으로 gradient를 계산하는 AutoGrad함수를 정의할 수 있다. Tensor를 이용해 forward와 backward를 구성하면 알아서 그래프에 넣을 수 있다.
실제 ReLU함수를 PyTorch에서 구현해본 식이다. ReLU의 forward와 backward를 torch.autograd.Function에 정의해주면 Computational graph에 적용할 수 있다.
하지만 실제로는 이미 다 구현되어 내장돼있기 때문에 따로 autograd를 구성할 필요는 없다고 한다.

새로운 nn모듈을 정의한다. 전체 모델을 하나의 새로운 nn 모듈 클래스로 정의하는 자체 클래스를 작성한다.
다른 모듈이나 훈련 가능한 가중치 또는 다른 종류의 상태를 포함할 수 있는 일종의 신경망 계층이다.
1) 선형1과 선형2를 할당한다. 새로운 모듈 개체를 구성한 다음 이를 자체 클래스 내부에 저장한다.
2) forward pass에서 자체 내부 모듈과 변수에 대한 임의의 autograd 연산을 사용하여 네트워크의 출력을 계산한다.

미니배치 구축, shuffling, multithreading을 처리한다.
원하는 소스에서 특정 유형의 데이터를 읽음 -> 데이터 로더에 래핑
for 문을 통해 데이터의 미니배치가 생성된다
Tensorboard vs Visdom: tensorboard로 계산 그래프의 구조를 시각화할 수 있다 하지만 visdom은 없다
코드 상 비교

TensorFlow: 계산 그래프를 구축하고 동일한 그래프를 재사용하여 계산 그래프를 여러 번 반복 수행한다. (정적 계산 그래프)
Pytorch: 각각의 forward pass가 새로운 그래프를 정의한다. (동적 계산 그래프)


정적 vs 동적: 정적일 경우 프레임워크가 해당 그래프에 들어가 최적화를 수행할 수 있다. 정적 그래프를 사용하면 그래프를 만들면 데이터 구조가 메모리에 있을 것이다. 이 데이터 구조를 가져와서 디스크에 직렬화 한다. 동적 그래프는 해당 모델을 재사용하려면 원본 코드가 필요하다. 그리고 코드가 훨씬 깔끔하다.
=> TensorFlow Fold: TensorFlow에서 동적인 그래프 코드를 만들 수 있다. (하지만 여전히 어색하다고 함)
TensorFlow가 안전하고 production 배포에 좋지만 코드가 안 예쁘고 Pytorch가 research에 좋다. Caffe(2)도 고려하장!
'CS231n' 카테고리의 다른 글
| CS231n(10) Recurrent Neural Networks (0) | 2024.03.13 |
|---|---|
| CS231n(9) CNN Architectures (1) | 2024.03.12 |
| CS231n(7) Training Neural Networks II (3) | 2024.03.08 |
| CS231n(6) Training Neural Networks I (0) | 2024.03.07 |
| CS231n(5) Convolutional Neural Networks (0) | 2024.03.05 |



