지난 강의 복습)
NN을 학습시키는 방법:
-대부분의 경우 기본적인 ReLU를 선택한다
-Weight initialization에서 초기 가중치가 너무 작으면 활성화가 사라지고 너무 크면 폭발한다
-Xavier를 사용하면 적당하다
-normalization을 하는 이유: 손실이 매개변수 벡터에 매우 민감하여 학습이 어려울 수 있다.
-batch normalization: 네트워크 내부에 추가 레이어를 추가해서 모든 중간 활성화가 평균 0과 단위 분산이 되도록 한다
용어 정리)
-epoch: 데이터를 학습시키는 횟수
-iteration: 한번의 epoch에서 모든 데이터를 한꺼번에 집어넣을 수 없어서 데이터를 나누어서 주는데 이때 나누는 횟수
-batch size: 각 iteration마다 주는 데이터 사이즈

전체 2000개의 데이터가 있고 epochs = 20, batch size = 500이라고 하자
그러면 1 epoch에 4번 iteration이 이루어지고 epoch가 20이니 80번의 학습이 이루어진다
앞서 봤던
오늘 요약)
NN을 더 최적화하기 위한 gradient update와 regularization:
-fancier optimization
-regularization
-transfer learning
0) 배치 경사하강법(Batch Gradient Descent, BGD)
: 한 번의 가중치 업데이트에 모든 데이터를 사용하므로 batch size가 전체 데이터 개수인 방법이다. 이 방법은 모든 데이터를 사용하여 기울기를 계산하고, 가중치들을 업데이트한다. 따라서 손실 함수의 최솟값에 안정적으로 수렴한다는 장점이 있지만, 모든 데이터를 사용하기 때문에 데이터가 많아지면 연산량이 매우 많고 메모리를 소비가 심하며 학습시간이 증가하여 결국 모델의 성능을 하락시키는 단점이 있다.

1) Stochastic Gradient Descent (확률적 경사하강법)
:초기에 설정한 학습률을 이용하여 손실함수(loss)의 값이 최소가 되는 방향으로 가중치를 업데이트하는 방법
위 방법을 해결하기 위한 방법으로
확률적으로 데이터를 뽑아 한 번의 반복당 한 개의 데이터를 사용하여 가중치들을 업데이트한다. 즉 배치의 크기가 1이다. 전체 데이터를 사용하는 경사하강법과 달리 SGD는 연산량이 비교적 매우 적어 손실 함수의 최적값에 빠른 수렴 속도를 보이고 메모리 소비량이 적다. 하지만 최적값에 수렴하지 않을 가능성이 있어 수렴 안정성이 낮고, 진폭이 매우 크다. 또한 연산량이 적어 GPU의 자원을 모두 활용하지 못한다.

문제1 ) taco-shell problem

x축 방향으로는 완만하고 y축 방향으로는 되게 급하다. 수평 방향인 x축 방향으로 이동하면 매우 느리고, 수직 방향인 y축 방향으로 가면 비교적 빠르다. loss가 수직 방향으로만 sensitive해서 동일하게 이동하지 못하고, x와 y 벡터의 합인 지그재그로 이동하게 되는 것이다. 이는 high demension일수록 더욱 문제가 심각해진다.
문제2) local minima, saddle point

local minima: 극대값들 사이의 극소값(기울기가 0이 되는 지점)에 안착하게 되는 경우이다. SGD 알고리즘은 기울기의 방향에 따라 이동하면서 기울기가 0인 지점을 loss의 최소값으로 찾아 최적점으로 인식하는 원리라서 해당 지점(local minima)에서 더 이상 update가 이뤄지지 않는다. (x += learning_rate * dx 에서 dx가 한번 0이 되면, 그 지점을 벗어나지 못하게 된다. 더 내려가면 loss의 진짜 최저점이 있는데, 그 전에 멈춰버린다.)
saddle point: 데이터가 더욱 고차원일수록 잘 일어나고, 기울기 0의 주변 지점의 기울기가 매우 작아져서 update도 굉장히 느려진다.
문제 3) Stochastic 문제

mini-batch를 쓰는 SGD 알고리즘은 batch마다 loss를 계산해서 전진해 나가는데, 이러한 방식이 expensive, 혹은 비효율적이다.
또한 mini-batch마다 update를 위해 추정값을 이용하는데, 이것이 엄청나게 noise를 일으킨다. 이 noise가 바로 위 그림에서 보이는 불규칙적인 형태의 선을 의미한다. W를 쪼개서 추정값을 이용하는 방식이라 noise가 쌓이고 쌓여서 저런 선이 나타납니다.
해결책 1) SGD + Momentum

: 모멘텀(운동량)을 주는 방법이다. 물리학적으로 가속도를 주는 개념이다.
우측의 코드 구성 중 vx부분이 중요한데, 이는 기울기가 아닌 rho * vx로 step이 이루어져 있어서 기울기가 0인 지점에서도 가속도를 주며 update가 되도록 하는 알고리즘이다.
여기서 v는 가속도를 의미하며, rho는 보통 0.9, 0.99를 이용하여 가속도에 약간의 마찰값을 넣어주는 파라미터이다.
매 step에서 old velocity에 friction으로 감소시키고, 현재의 gradient를 더해준다.

슬라이드의 공은 기울기가 0인 지점에서도 가속도로 step하기 때문에 update가 진행된다.
또한 taco shell 문제를 해결해준다. 기존 SGD는 빨간색 선처럼 지그재그 형태로 최적화 되었기 때문에 비효율적이고 느린 반면, 모멘텀 + SGD는 모멘텀이 수평방향으로 가속도록 유지하여 민감한 방향으로 총합을 줄여주어 noise들을 평균화시켜 줄 수 있다. 그래서 파란색 곡선처럼 매끄럽게 최적화가 가능해진다.
해결책2) Nester momentum

우측에는 Nesterov Momentum에 관련된 그림이 나오는데 우선 그림의 의미만을 놓고 볼 때는 velocity의 위치에서 방향을 예측한 후 gradient를 계산해서 actual step을 그리는 것이다. 이를 error correction term이라고 한다.

복잡해보이는데 정리하면 현재 v에서 step을 밟고 거기서 gradient를 계산하는 것이다.
현재 지점(x~t)에서 현재 velocity()를 더하고 현재 v()와 이전 v()의 차이를 더해준다.
옆에 코드에서 x += -rho*old_v + (1+rho)*v 가 그 부분이다.
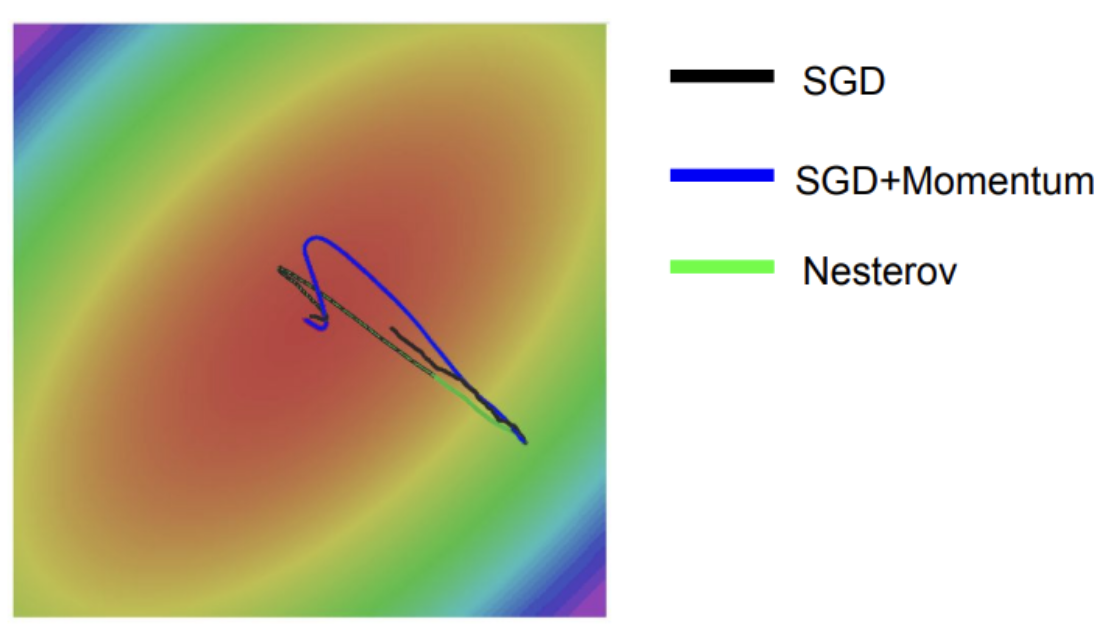
SGD는 느리고 momentum과 Nesterov는 약간 오버슈팅한 형태를 나타내는데, 이게 가속도가 있는 velocity 때문이다.
momentum과 Nesterov(네스테로프)의 차이점은 네스테로프가 오버슈팅이 덜 일어난다는 점이다.
현재 velocity와 old velocity 간의 차이를 더해준 error correction term 효과로 인한 것 같다.

해결책 3) AgaGrad
손실 함수 곡면의 변화에 따라 적응적으로 학습률을 정하는 알고리즘
곡면이 많이 변하면 최적해에 접근했을 거라는 가정으로 작게 이동하고 반대일 경우 많이 이동한다


grad_squared를 이용한다. 가속도가 아닌 기울기의 제곱값을 이용하는 것이다.
학습중에 기울기의 제곱값을 grad_squred에 계속 더해나가서 update step에서 나눠 준다
small gradient인 경우에는 grad_squared가 작은 값으로 나눠주니 속도가 더 잘 붙고
large gradient인 경우에는 큰 수로 나누어서 wiggling dimension은 slowdown해서 천천히 내려오게 된다.
단점) 곡면의 변화량을 전체 경로의 기울기 벡터의 크기로 계산했다. 그래서 학습이 진행될수록 변화량은 커지는데, 적응적 학습률은 점점 낮아진다.
만약 경사가 매우 가파른 곳에서 학습을 시작한다면, 초반부터 적응적 학습률이 급격히 감소하다가 최적해에 도착하기 전 조기 종료될 가능성이 있다.
해결책4) RMS Prop

실제 gradient에 해주는게 아닌 grad_squared에 해주는 차이가 있다.
변화량이 더 클수록 학습률이 작아져서 조기 종료되는 문제를 해결하기 위해 학습률 크기를 비율로 조정할 수 있도록 제안된 방법

장점) 미분값이 큰 곳에서는 업데이트 할 때 큰 값으로 나눠주기 때문에 기존 학습률 보다 작은 값으로 업데이트되어 진동을 줄이는데 도움이 되고 미분값이 작은 곳에서는 업데이트 시 작은 값으로 나눠주기 때문에 기존 학습률 보다 큰 값으로 업데이트 된다.
이는 조기 종료를 막으면서도 더 빠르게 수렴하는 효과를 불러온다.
매번 새로운 gradient 제곱의 비율을 반영하여 평균을 업데이트 하는 방식이다.
참고) 지수가중 이동평균
: 데이터의 이동 평균을 구할 때, 오래된 데이터가 미치는 영향을 지수적으로 감쇠하도록 만들어주는 방법

해결책 5) Adam
Momentum과 RMSProp이 합쳐진 형태이다.
진행하던 속도에 관성도 주고, 최근 경로의 곡면의 변화량에 따른 적응적 학습률을 갖는 알고리즘이다.
개념)
1. 1차 관성으로 속도를 계산한다.
속도에 마찰 계수 a 대신에 가중치 β1을 곱해서 gradient의 지수가중이동평균을 구한다.
2. 2차 관성으로 (gradient)의 지수가중이동평균을 구한다.
3. 마지막은 parameter 업데이트 식으로 1, 2차 관성을 사용한다.



Second Order Optimization
SGD, AdaGrad, RMSProp, Adam은 모두 First-Order Optimization으로 한번 미분한 weight만 optimize에 반영되었다.
그러나 1차 함수로만 optimize하기 때문에 graident 수정이 제한적이다. 이를 보완하기 위해 고차 함수 optimization이 등장하였다.
그러나 고차 함수 optimization은 역전파를 위해 역행렬을 구할 때, 시간 복잡도가 엄청나게 증가한다 (ex)가중치의 차원이 몇 백만 차원으로 늘어남) 이러한 이유로 아직까지는 First-Order Optimization을 사용한다

(잘 안 쓴다고하니 이런게 있구나 하고 넘어갔다)
Model Ensembles
여러 모델들을 평균내서 이용하는 앙상블 모델은 최종 성능에서 1~2% 성능을 끌어올리는 데에 많이 이용한다
독립적으로 모델을 교육하는 대신 단일 모델의 여러 스냅샷을 사용한다
우리가 learning rate을 빨랐다가 느렸다가 반복하면 model이 converge to different regions in the objective landscape. 이러한 snapshot들을 ensemble하면 model을 한번 훈련시킴에도 불구하고 결과가 좋다

Dropout
: train data에 모델이 overfitting되는 것을 줄이고 처음 본 data에도 잘 작동하게 하기 위해서 일종의 regularization이다.


Drop-out은 서로 연결된 연결망(layer)에서 0부터 1 사이의 확률로 뉴런을 제거(drop)하는 기법이다.
foward pass 과정에서 일부 뉴런의 activation 값을 0으로 만들어 버린다.
예를 들어, 위의 그림과 같이 drop-out rate가 0.5라고 가정하자. Drop-out 이전에 4개의 뉴런끼리 모두 연결되어 있는 전결합 계층(Fully Connected Layer)에서 4개의 뉴런 각각은 0.5의 확률로 제거될지 말지 랜덤하게 결정된다.
Drop-out Rate는 하이퍼파라미터이며 일반적으로 0.5로 설정한다. 이는 과적합을 막기 위함이다

-redundancy(중복성)을 줄이는 의미가 있다.
노드를 랜덤하게 끄게 되어도, 남은 노드들이 꺼진 노드가 학습하던 부분을 대신 더 학습하게 된다
-일종의 ensemble 방식이다.
train epoch를 돌 때마다 랜덤으로 바뀌는 노드의 구성이 변하기 때문에 마치 여러모델의 값을 평균내는 ensemble의 효과를 갖는다.

함수 의미)
가중치 w와 입력 x에 대한 함수 f(x)가 있으면 이 수식에 z가 추가되고 이때 z는 random을 뜻한다.
z가 임의적으로 0이 되면 f(x)의 값이 0이 된다. Dropout을 사용하게 되면 전체 학습시간이 늘어난다. 각 스텝마다 업데이드되는 파라미터의 수가 줄어들기 때문이다. 다시 말해 Dropout을 사용하게 되면 전체 학습시간은 늘어나지만 모델이 수렴한 후에는 더 좋은 일반화 능력을 얻을 수 있다.

<코드>

위의 코드에서 train시 forward pass에서 2줄을 추가해 0으로 만들 노드를 랜덤으로 뽑는다(아래 코드).
그리고나서 선택받은 H1,H2 노드들에 확률값을 곱해준다.

의미)
학습중에는 train에 너무 fit하지 않게 네트워크에 랜덤성을 부여한다. 그리고 test에서는 이런 randomness들을 average out 시켜서 일반화를 시켜준다.
이런 아이디어는 Batch norm과 유사하다.
Batch norm도 일반화를 위해 학습 중에 1개의 data point가 각각 다른 여러 minibatch에서 다른 data들과 배치를 이룬다.
test시에는 이 미니배치의 확률들(랜덤성)을 global 추정값들을 써서 average out 시킨다.
따라서 대개는 Batch norm으로 충분하지만, 일부 overfitting이 과한 경우 dropout을 추가하는 등 적절히 사용하면 된다.
Data Augmentation
:기존의 학습 데이터를 변형하거나 확장하여 학습 알고리즘이 더 일반적이고 강건한 모델을 학습하도록 돕는 기술이다. 오버 피팅을 줄이기 위한 목적이 있다. 이미지 회전, 반전, 크롭, 스케일링 등의 방법들이 있다.
DropConnect

dropconnect는 output값이 아닌 w 매트릭스를 랜덤으로 0으로 조정하는 기법이다.
Dropout은 뉴런을 제거하여 과적합을 방지하는 반면, Dropconnect는 연결의 일부를 제거하여 과적합을 방지한다.
Fraction Max Pooling
입력 영역의 크기를 정확히 반으로 나누지 않고 부분적으로 선택하여 이는 입력 영역의 크기를 조절할 수 있는 유연성을 제공한다.
Pooling을 연산할 때, spot을 랜덤으로 연산한다.

Stochastic Depth
스토캐스틱 뎁스는 신경망의 깊이(Depth)를 확률적으로 줄이는 방식으로 작동한다.
일반적으로 딥러닝 모델은 깊어질수록 과적합의 위험이 높아지는데, 스토캐스틱 뎁스는 이러한 문제를 완화한다.
신경망의 각 레이어에 대해 특정 확률에 따라 해당 레이어를 활성화시키지 않거나 제거한다.

아래 3개는 중요성이 떨어지는 거 같다.
Transfer Learning

1번과 같이 많은 양의 데이터로 학습시킨 CNN 네트워크가 있다고 하자. ImageNet 처럼 큰 data로 학습을 시킨 알고리즘은 1000개의 클래스로 분류할 수 있다.
이제 많은 카테고리중 작은 카테고리로 분류할 것이다. 가령 1000개의 카테고리를 4개의 카테고리로 줄인다고 생각하자
2번에서 현재 데이터셋의 양이 적은 경우 가장 마지막의 FC레이어가 최종 feature를 class score로 배출하는 층인데, 이걸 초기화시킨다.
원래 image net에서는 학습을 4096*1000 차원이었는데, 4개의 class로만 분류하기 위해 4096*4로 바꾼다.
그리고 last layer말고 나머지는 전부 freeze시키고 마지막 layer만 가지고 지금 가진 작은 데이터셋을 학습시킨다
3번에서 데이터의 양에 따라서 train을 다시 시킬 layer를 약간 조정해주는 fine tuning을 생각해볼 수 있다.
이미 잘 학습된 모델이기에 learning rate값을 조금 낮추면 좋다.

오른쪽 표처럼 4가지 경우대로 하면 된다.
'CS231n' 카테고리의 다른 글
| CS231n(9) CNN Architectures (1) | 2024.03.12 |
|---|---|
| C231n(8) DeepLearning Software (0) | 2024.03.10 |
| CS231n(6) Training Neural Networks I (0) | 2024.03.07 |
| CS231n(5) Convolutional Neural Networks (0) | 2024.03.05 |
| CS231n(4) Introduction to Neural Networks (0) | 2024.03.04 |



