Process the data (데이터 전처리)

일반적인 머신러닝에서 데이터를 zero-centering 후에, normalize 하여 각각의 들쑥날쑥한 피쳐들을 어떤 범위 내로 전처리시킨다. 하지만, 이미지 데이터에서는 zero-centering만 해준다. 왜냐하면 이미지 데이터는 픽셀 값이 0에서 255로 전부 같은 범위이기 때문이다.
Weight Initialization
1. W에 아주 작은 랜덤의 값을 부여한다.
정규 분포로부터 가져온 작은 편차의 값들을 랜덤으로 w initialization 해준다
W=0.01*np.random.randn(D,H)하지만 여전히 neural net이 깊어지면 문제가 발생한다.

위의 코드를 보면 각 hidden layer에 input으로 X=(1000, 500) 가 들어오고 각각 W=(500, 500) 가중치로 가중합스코어를 구한 뒤 활성함수 tanh(x)를 적용해 output X=(1000, 500)를 출력해 다음 layer에 넣어주는 뉴럴네트워크를 생성한다.

아래 파란색 10개의 분포는 10개의 layer에서 나온 값들의 분포이다. 파란색 그래프는 평균 값이고 빨간색 그래프는 표준편차이다. 분포가 zero mean이지만 layer가 깊어질수록 편차가 사라져서 그냥 0으로 수렴한다. 이는 tanh함수가 zero-centered 함수이기 때문이다. 따라서 0.01을 곱해서 w에 작은 값을 initialize 하면 0으로 수렴해서 안 좋다는 뜻이다

이번에는 1을 곱했더니 출력 값들이 1과 -1로만 가버려서 explode한다. tanh 함수에서 1과 -1 값들의 기울기는 0이 되는 saturated 지점이라 update 되지 않은 것이다

이번에는 initialization이 잘 된 예로 Xavier initialization이다. Xavier는 랜덤의 가우시안 분포 값에서 np.sqrt(fan_in)으로 나누어주어(W=0.01*np.random.randn(D,H) / np.sqrt(fan_in))스케일링의 방식을 해주는 것이다. 고정 값을 곱해서 w를 주는 것보다 상대적으로 입력값의 개수에 따라 상대적으로 값을 조절하여 initialization을 해주기 때문에 합리적이다
입력값들의 수가 적으면 우리는 큰 값의 w가 필요하다. 그래서 더 적은 수로 나누어 스케일링해주고, 반대로 입력값들의 수가 많으면 우리는 작은 값은 w가 필요해서 큰 수로 나누어 스케일링을 한다.
하지만 이 방식은 비선형 함수인 ReLu를 이용하면, 다시금 문제가 발생한다.

zero - mean 함수였던 tanh와는 다르게 ReLu는 음수 부분은 전부 0이 되기 때문에 위와 같은 그래프가 나타난다. 활성화 함수를 지나면서 편차가 강제로 절반이 된다. 출력 값들이 0이 많다면 w의 update가 잘 이루어지지 않는다
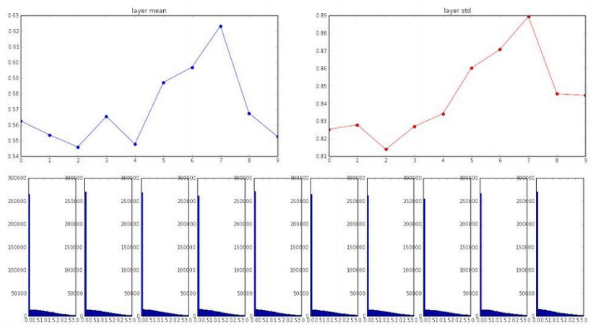
따라서 np.sqrt(fan_in/2)로 수정하여 2로 더 나누어준다. ( W=0.01*np.random.randn(D,H) / np.sqrt(fan_in/2) ) 뉴런의 절반이 죽어버린다는 근거로 2를 더 나눈 것이다. 마지막 layer에도 출력값이 살아있는 게 보인다.
Batch Normalization (배치 정규화)
배치 정규화는 학습하는 과정 자체를 전체적으로 안정화하여 학습 속도를 가속 시키기 위함이다.
학습에서 불안정화가 일어나는 이유를 'Internal Covariance Shift' 때문이다. 이는 네트워크의 각 레이어나 Activation 마다 입력값의 분산이 달라지는 현상을 뜻한다.
Covariate Shift : 이전 레이어의 파라미터 변화로 인하여 현재 레이어의 입력의 분포가 바뀌는 현상
Internal Covariate Shift : 레이어를 통과할 때 마다 Covariate Shift 가 일어나면서 입력의 분포가 약간씩 변하는 현상
Whitening
이 현상을 막기 위해 간단하게 각 레이어의 입력의 분산을 평균 0, 표준편차 1인 입력값으로 정규화 시키는 Whitening이 있다. Whitening은 들어오는 입력값의 특징들 간에 상관관계를 줄이고, 각각의 분산을 1로 만들어준다.
이는 covariance matrix의 계산과 inverse의 계산이 필요하기 때문에 계산량이 많고 whitening은 일부 파라미터들의 영향이 무시된다.
예를 들어 입력 값 X를 받아 Z = WX + b 라는 결과를 내놓고 적절한 bias b 를 학습하려는 네트워크에서 Z에 E(Z) 를 빼주는 작업을 생각해보면, 이 과정에서 b 값이 결국 빠지게 되고, 결과적으로 b의 영향은 없어진다. 단순히 E(Z)를 빼는 것이 아니라 표준편차로 나눠주는 등의 scaling 과정까지 포함될 경우 이러한 경향은 더욱 악화 된다.
이렇듯 단순하게 Whitening만을 시킨다면 이 과정과 파라미터를 계산하기 위한 최적화(Backpropagation)과 무관하게 진행되기 때문에 특정 파라미터가 계속 커지는 상태로 Whitening 이 진행 될 수 있다.
Batch Normalization
Whitening을 해결하기 위해 도입된다. 배치 정규화는 평균과 분산을 조정하는 과정이 별도의 과정으로 떼어진 것이 아니라, 신경망 안에 포함되어 학습 시 평균과 분산을 조정하는 과정 역시 같이 조절된다는 점에서 단순 Whitening 과는 구별된다. 즉, 각 레이어마다 정규화 하는 레이어를 두어, 변형된 분포가 나오지 않도록 조절하게 하는 것이 배치 정규화이다.

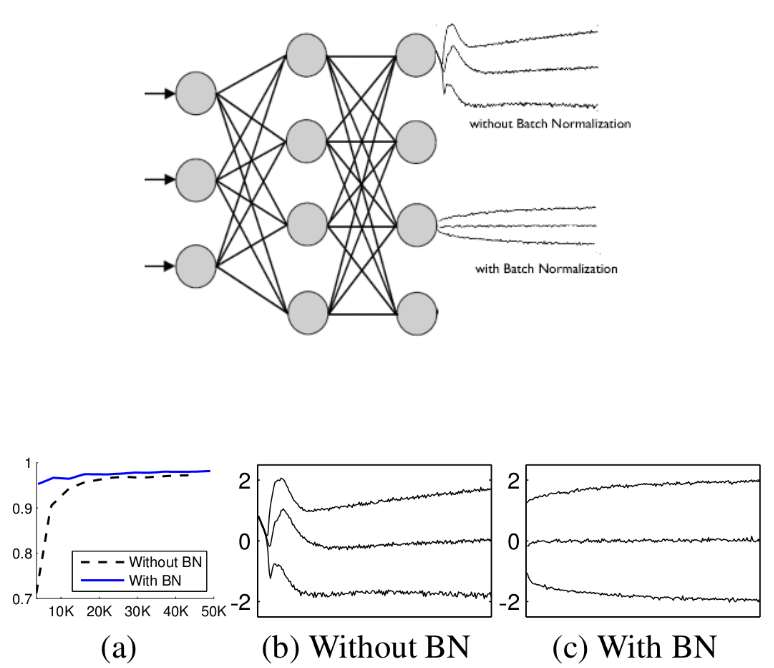
그림과 같이 완전 연결층(Fully Connected Layer)과 활성화 함수 사이에 배치 정규화 층(Batch norm layer)을 하나 더 삽입한다. 각각의 층에서 가중치 w들이 곱해지기때문에 layer를 지날때마다 범위가 튀기 때문에, 층마다 이렇게 batch norm을 넣어주어 normalize를 진행한다.
배치 정규화 층에서는 FC에서 계산된 값을 미니배치 단위로 정규화 한다. 미니배치 B의 사이즈가 m이라면 각 데이터의 평균 μB 와 분산 σ^2B 를 구하고 표준화(Standardization)을 수행하여 xi^를 구한다. 이때 ϵ은 계산 안정성을 위한 매우 작은 상수이다.

이렇게 계산하면 표준정규분포 N(0,1)을 나타내는데 표준정규분포는 68.26%가 [-1,1]에 있고 95.44%가 [-2,2] 범위에 있다. 근데 이 구간에서는 시그모이드 함수가 선형 함수와 유사하다.

활성화 함수로 선형 함수를 사용하면 층을 깊게 쌓을 때의 이점이 사라지기 때문에 정규화한 xi을 적당히 조작해줘야 한다. 파라미터 γ,β를 각각 곱해주고 더해준 값 yi를 활성화 함수에 입력한다.

곱해지고 더해지는 파라미터 γ,β는 각 노드마다 다른 값이 적용된다. 특정 층의 노드가 64개라면 배치 정규화 층에도 파라미터가 각각 그만큼 있는 것이다. γj,βj(j=1,⋯,64)가 된다. 이 때 y의 분포는 N(βj,γ^2j)이며 γi,βi는 Backpropagation을 통해서 학습이 된다. 여기서 감마는 표준 편차이기 때문에 scaling의 효과를 주고, 베타는 평균 값이기 때문에 shift의 효과를 준다.
Babysitting the Learning Process
<단계>
1) 데이터 전처리한다
2) 네트워크의 아키텍를 구성한다
3) loss 함수를 지정하거나 regularaization이 0 -> 0.001일 때 변화를 관찰한
4) 학습을 시키는 sanity check으로 먼저 진행한다. train 셋에서 일부만 가져와서 시작한다. 과적합이 되면 학습이 잘 되는 것을 확인한다.
5) 전체 데이터를 학습 시키고 loss를 확인하면서 learning rate를 조정한다.
Hyperparameter Optimization
: 하이퍼파라미터는 모델의 구조나 학습 과정을 제어하는데 사용되는 매개변수로, 학습률, 은닉층의 개수, 은닉층의 뉴런 수 등이 있다. 이들은 모델의 학습과 성능에 직접적인 영향을 미치므로, 적절한 값을 설정해야 한다.
1) Cross validation strategy
데이터를 여러 개의 subset으로 나눈 뒤, 각 subset을 훈련 데이터와 검증 데이터로 번갈아가면서 사용하여 모델을 평가한다. 가장 일반적인 방법은 K-fold Cross Validation으로, 데이터를 K개의 subset으로 나눈 뒤, K번의 반복 중 각각의 subset을 검증 데이터로 사용하고 나머지를 훈련 데이터로 사용한다.

먼저 reg(regularization)값과 lr(learning rate) 값의 범위를 지정해준다.
이때 log scaling을 해주는데 결과를 안정적으로 만들기 위함이다. 따라서 reg는 10^-5부터 10^5 까지 lr은 10^-3부터 10^-6까지 10의 지수 형태로 무작위로 값을 선택한다.
two_layer_net이라는 두 개의 레이어로 이루어진 신경망 구조를 생성하는 함수를 사용하고 전체 데이터셋을 5번 반복한다. update는 최적화 알고리즘의 업데이트 방법을 지정하고 여기서는 momentum을 사용한다. sample_batches가 true이면 미니배치를 사용해서 훈련한다.
trainer.train함수로 학습하고 max_count 만큼 반복하면서 여러 번의 실험을 진행하고, 가장 우수한 성능을 보이는 하이퍼파라미터 조합을 찾는다.
결과적으로 lr이 e-4, reg가 e-01인 부분에서 높은 validation accuracy가 나온다. 이를 기준으로 (-5, 5) (-3, -6)에서 (-4, 0) (-3, -4)로 조정한다.

이를 위해 주로 grid search random search를 사용한다.

loss function를 해석하는 방법에 대한 설명이다. 초기엔 빠르게 감소하다가 점점 감소폭이 작아지는 빨간색 그래프가 적합하다. lr 값의 update 속도와 방향의 정도가 적당하다.

모니터링하다보면 왼쪽과 같이 초반엔 전혀 학습이 일어나지 않다가 어느순간 loss 값이 급격하게 감소한다. 이는 초기 initialization이 제대로 수행되지 않은 것으로 w 값이 너무 작은 경우이다. gradient의 업데이트가 제대로 일어나지 않아서 best 값으로의 시간이 오래 걸린다.
오른쪽은 학습이 제대로 진행되는지를 보여주는데 두 선이 멀다면 (training acc는 높아지고 validation acc는 낮아짐 또는 반대) 이는 과적합되었을 가능성이 있다. 이땐 regularization을 높여주는 방법이 있다.
과적합: 머신러닝 모델이 훈련 데이터에 너무 맞추어져서 새로운 데이터에 대한 일반화 능력이 저하되는 현상이다. 모델이 훈련 데이터에 너무 가깝게 학습되어서 훈련 데이터에 대해서는 높은 성능을 보이지만, 새로운 데이터나 테스트 데이터에 대해서는 성능이 낮아진다.
'CS231n' 카테고리의 다른 글
| C231n(8) DeepLearning Software (0) | 2024.03.10 |
|---|---|
| CS231n(7) Training Neural Networks II (3) | 2024.03.08 |
| CS231n(5) Convolutional Neural Networks (0) | 2024.03.05 |
| CS231n(4) Introduction to Neural Networks (0) | 2024.03.04 |
| CS231n(3-3) Loss Functions and Optimization (0) | 2024.02.22 |



