실습) Iris 데이터셋
-설명
꽃의 꽃잎과 꽃받침의 길이와 너비가 주어진다. Iris-setosa, Iris-versicolor, Iris-virginica라는 3가지 꽃에 대한 측정이다
X에 sepal-length ~ petal-width까지의 feature 데이터를 담고, y에 Class(꽃의 종류)를 담는다. 이후 feature scaling(정규화)를 해준다 ; feature scaling은 들쭉날쭉한 데이터 크기 분포의 scale을 상대적으로 잡아주는 것


Linear Classification
-Parametric model 이란?

입력 이미지: x
파라미터 (가중치) : W
CIFAR10 데이터셋을 이용하고, 고양이 사진을 x라 할때, 함수 f는 x와 w를 가지고 10개의 숫자를 출력한다
이 10개의 숫자는 data-set의 각 클래스에 해당하는 score의 개념으로, "고양이" 스코어가 높다면 "고양이"일 확률이 큰 것
KNN에서는 파라미터를 이용하지 않았고, 전체 트레이닝 셋을 Test time에서 다 비교하는 방식임
트레이닝 셋이 뭐고 Test time이 뭐지?
(트레이닝 셋은 모델이 학습하는 데이터이고, 테스트 타임은 이 학습된 모델을 기반으로 새로운 데이터를 분류하거나 예측하는 시간임)
parametric 접근법에서는 train 데이터의 정보를 요약해서 파라미터 w에 모아주는 것이라 생각할 수 있음
따라서 test time에 더이상 트레이닝 데이터를 직접 비교하지 않고, W만 사용할 수 있음
딥러닝이란 여기서 이 함수 f를 잘 설계하는 일!

먼저 입력 이미지(32x32x3)을 하나의 열벡터로 피면 (3072x1)이 된다. 이 x를 W와 곱했을 때 10개의 스코어가 나와야 되므로, W는 10x3072가 되어야하고, 결론적으로 10x1의 스코어를 가져다 줄 수 있다
b는 데이터와 무관하게 (x와 직접 연산되지 않음) 특정 클래스에 우선권을 부여한다


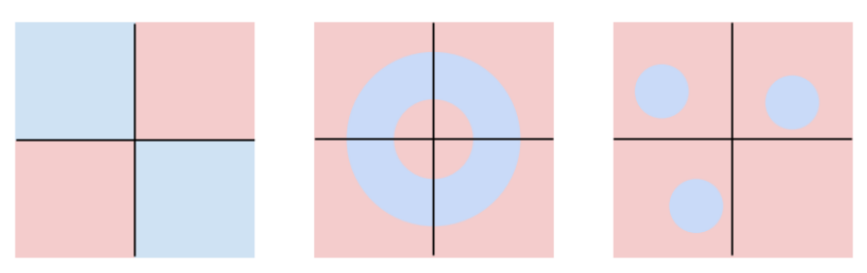
이미지를 고차원 공간의 한 점이라고 생각하면, Linear classifier은 아래와 같이 각 클래스를 구분시켜주는 선형 boundary 역할을 하지만 아래와 같은 데이터 셋은 선형분류하기 힘들다.
'CS231n' 카테고리의 다른 글
| CS231n(4) Introduction to Neural Networks (0) | 2024.03.04 |
|---|---|
| CS231n(3-3) Loss Functions and Optimization (0) | 2024.02.22 |
| CS231n(3-2) Loss Functions and Optimization (0) | 2024.02.21 |
| CS231n(3-1) Loss Functions and Optimization (0) | 2024.02.15 |
| CS231n(1) Introduction to Convolutional Neural Networks for Visual Recognition (1) | 2024.02.14 |



