Loss function (손실함수)
: Linear Classifier에서 W의 성능이 중요하다 W를 평가하는 척도가 됨
손실 함수에서 사용되는 data loss는 주어진 data point 에 대한 모델의 예측값과 실제 레이블 간의 차이를 나타내며, 이 차이가 작을수록 모델의 성능이 좋다고 판단됨
1) Multiclass SVM loss
:손실함수 중에서 가장 기본적이고 이미지 분류에도 성능이 좋음
주어진 샘플에 대한 각 클래스의 스코어와 올바른 클래스의 스코어를 비교하여 마진을 계산하고, 마진이 양수인 경우에만 손실을 계산
(스코어란 클래스를 log화한 확률)
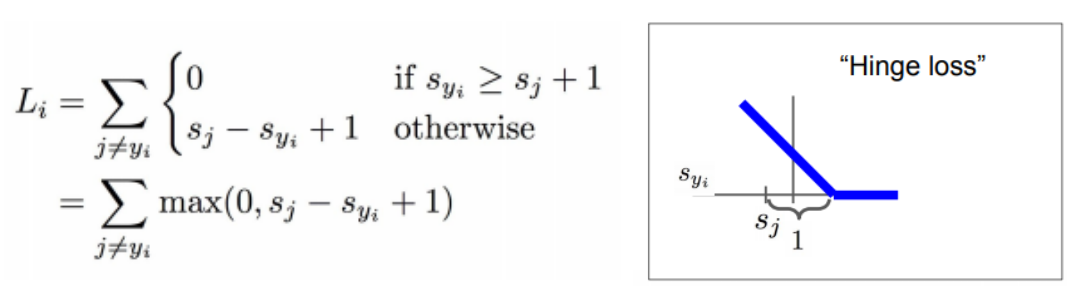
sj: 오답 카테고리의 스코어
syi: 정답 카테고리의 스코어

첫번째 데이터에 대한 Loss를 구해보자 cat 일 때 syi = 3.2 이다.
j가 car 이면, 3.2 >= 5.1 + 1 이 성립하지 않으므로 5.1-3.2+1 = 2.9 이다
j가 frog 이면, 3.2 >= -1.7 + 1 이 성립하므로 0이다
따라서 첫번째는 2.9+0 =2.9 이다
두번째 데이터에 대한 Loss를 구해보자 car 일 때 syi = 4.9 이다.
j가 cat 이면, 4.9 >= 1.3 + 1 이 성립하므로 0 이다
j가 frog 이면, 4.9 >= 2.0 + 1 이 성립하므로 0이다
따라서 두번째는 0+0 =0 이다
세번째 데이터에 대한 Loss를 구해보자 frog 일 때 syi = -3.1 이다.
j가 cat 이면, -3.1 >= 2.2 + 1 이 성립하지 않으므로 2.2 + 3.1 +1 = 6.3 이다
j가 car 이면, -3.1 >= 2.5 + 1 이 성립하지 않으므로 2.5+3.1+1 = 6.6 이다
따라서 두번째는 6.3+6.6 = 12.9이다
( 2.9+0+12.9 ) / 3 = 5.27
여기서 syi >= sj + 1이면 0이 되는 조건에 1의 마진 값을 줌으로써 정답 카테고리의 스코어를 이 정도 맞췄으면 꽤 잘맞췄네? 하는 것이다. 마진을 크게하면 모델은 좀 더 널널하게, 작게하면 엄격하게 분류를 해야된다.
SVM(Support Vector Machine)을 벡터화하는 코드
: 손실을 최소화하는 방향으로 모델의 가중치를 업데이트

2) Regularization Loss
loss가 0인 W가 좋은 것일까? 사실 좋지 않은 일이다. w가 0이라는 것은 트레이닝 데이터에 완벽한 w라는 것인데, train set이 아닌 test 데이터의 성능이 더 중요하다
함수가 단순해야 test 데이터를 맞출 가능성이 더 커지기 때문에 이를 위해 Regularization을 추가 (모델의 복잡성을 제어)
Data Loss 와 Regularization loss의 합으로 변하고, hyper-parameter 인 람다로 두 항간의 trade-off를 조절함

따라서 regularization loss는 모델은 여전히 더 복잡한 모델이 될 가능성이 있으나, soft penalty인 regularization을 추가함으로써, 만약 너가 복잡한 모델을 계속 쓰고 싶으면, 이 penalty를 감수하라는 것 !
regularization loss 종류

- L2 정규화 (Ridge 정규화): 가중치 vector의 제곱합을 패널티로 사용한다. λ는 정규화 강도이고 n 은 가중치 벡터의 차원 수
- L1 정규화 (Lasso 정규화): 가중치 벡터의 절대값의 합을 패널티로 사용한다. 이는 일부 가중치 값이 0이 되는 희소한 모델을 유도할 수 있다.


x = [1, 1, 1, 1]
w1 = [1, 0, 0, 0]
w2 = [0.25, 0.25, 0.25, 0.25]
일때
w1는 오직 첫 번째 가중치만 0이 아닌 값이므로, L1 정규화는 첫 번째 가중치에만 패널티를 부여한다
w2는 모든 가중치가 동일한 값으로 구성되어 있으므로, L2 정규화는 모든 가중치에 동일하게 spread 한다
'CS231n' 카테고리의 다른 글
| CS231n(4) Introduction to Neural Networks (0) | 2024.03.04 |
|---|---|
| CS231n(3-3) Loss Functions and Optimization (0) | 2024.02.22 |
| CS231n(3-2) Loss Functions and Optimization (0) | 2024.02.21 |
| CS231n(2) Image Classification (0) | 2024.02.14 |
| CS231n(1) Introduction to Convolutional Neural Networks for Visual Recognition (1) | 2024.02.14 |



